
홍동이의 성장일기
[👩💻TIL 4일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
[서울시 물가정보분석]
[지하철 승하차현황 분석]
[파이썬 데이터시각화]
[62차시] 파이썬 3차시_목적에 따른 여러가지 그래프
[63차시] 파이썬 4차시_한글폰트사용, 생상, 마커, 선
[48차시] 서울시 일별 추가확진자 동향
구 별 확진자 동향
## 확진일-구별 확진자수 집계
# 피봇테이블 만들기
df_gu = pd.pivot_table(df, index='확진일', columns='지역', values='연번', aggfunc='count', margins=True)
# 서울시 일별 추가확진자 동향
s_date = df_gu['All'][:-1]
# 서울시 일별 추가확진자가 많았던 순으로 보기
s_date.sort_values(ascending=False)
# 서울시 일별 추가확진자 시각화
x = s_date.index
y = s_date.values
plt.plot(x,y)
plt.title('서울시 일별 추가확진자(2021.09.28)')
plt.xlabel('확진일')
plt.ylabel('추가확진자수')
plt.xticks(rotation=45)
plt.show()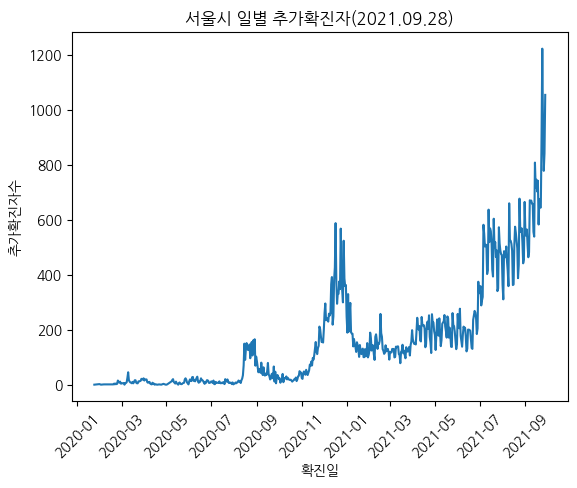
[49차시] 서울시 구별 추가확진자 및 접촉력 분석
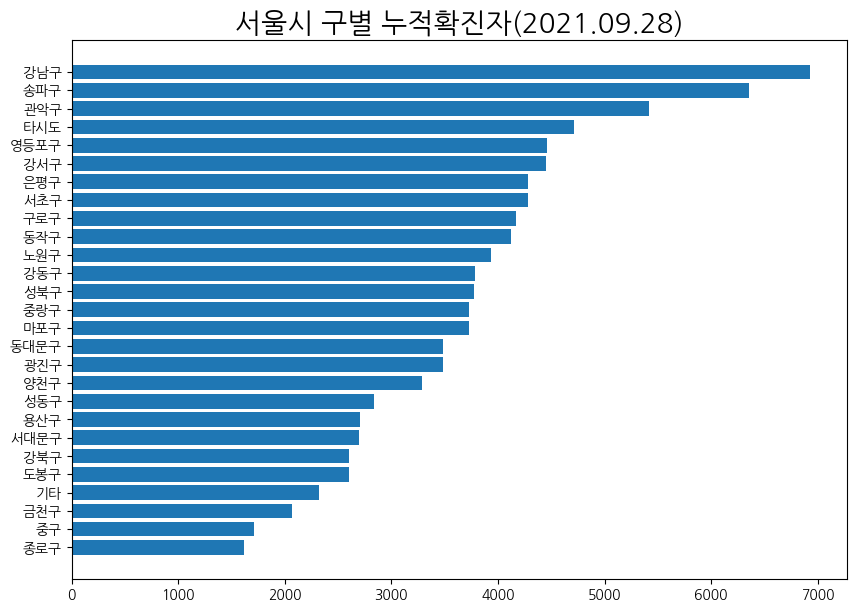
서울시 구별 누적확진자 비교
# 서울시 구별 누적확진자 많은 순으로 보기
s_gu = df_gu.loc['All'][:-1]
s_gu = s_gu.sort_values()
# 서울시 구별 누적확진자 많은 순으로 시각화
x = s_gu.index
y = s_gu.values
plt.figure(figsize=(10,7))
plt.title('서울시 구별 누적확진자(2021.09.28)', size=20)
plt.barh(x,y)
plt.show()
나는 누적확진자가 가장 큰 값을 위로 올리고 싶어서 sort의 ascending=False를 제거했다.
※참고: figsize는 상단에 위치해야한다
최근일 기준 지역별 추가확진자
s_gu = df_gu.iloc[-2][:-1]
s_gu = s_gu.sort_values()
x = s_gu.index
y = s_gu.values
plt.figure(figsize=(10,7))
plt.barh(x,y)
plt.show()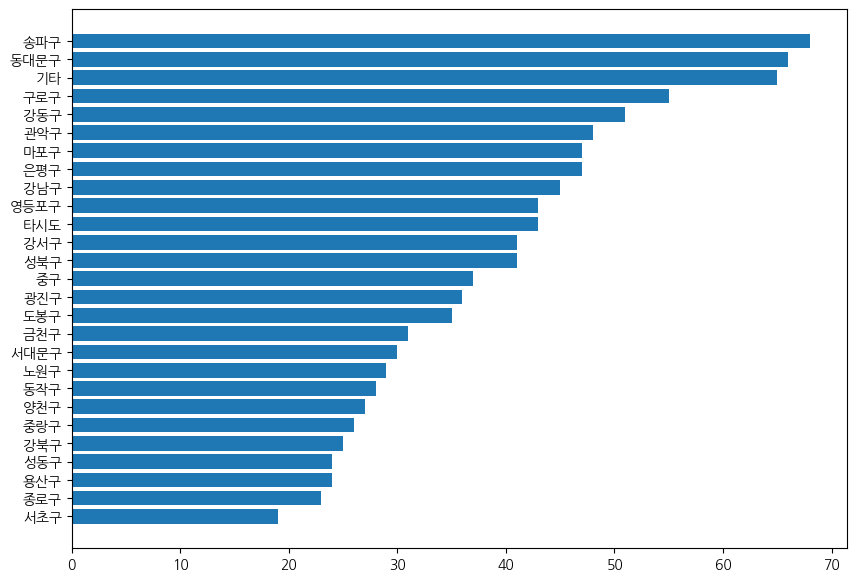
접촉력에 따른 확진 분석
## 접촉력에 따른 확진 건수 best 10
df['접촉력'].value_counts()[:10].to_frame()
## 최근월 접촉력에 따른 확진 건수 best10
df[(df['확진일'].dt.year==2021)&(df['확진일'].dt.month==9)]['접촉력'].value_counts()[:10].to_frame()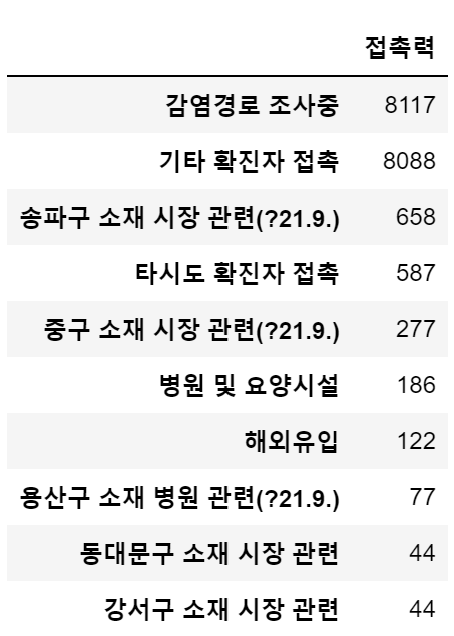
[50차시] 데이터 수집 및 전처리
import pandas as pd
# 그래프를 노트북 안에 그리기 위해 설정
%matplotlib inline
# 필요한 패키지와 라이브러리 가져온다.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
# 폰트 지정하기
plt.rcParams['font.family'] = 'gulim'
데이터 확인 및 전처리
## 2021년 공공자전거 대여이력 정보
# 데이터프레임 생성/확인
df1 = pd.read_csv('data/공공자전거 대여이력 정보_2021.01.csv', encoding='cp949', low_memory=False)
df2 = pd.read_csv('data/공공자전거 대여이력 정보_2021.02.csv', encoding='cp949', low_memory=False)
df3 = pd.read_csv('data/공공자전거 대여이력 정보_2021.03.csv', encoding='cp949', low_memory=False)
df4 = pd.read_csv('data/공공자전거 대여이력 정보_2021.04.csv', encoding='cp949', low_memory=False)
df5 = pd.read_csv('data/공공자전거 대여이력 정보_2021.05.csv', encoding='cp949', low_memory=False)
df6 = pd.read_csv('data/공공자전거 대여이력 정보_2021.06.csv', encoding='cp949', low_memory=False)
# 데이터 연결/확인
# concat
df = pd.concat([df1,df2,df3,df4,df5,df6])
# 데이터 크기
df.shape
# 데이터 정보(사용메모리)
df.info()
## 데이터 전처리
# 불필요한 컬럼 제거
# 자전거번호, 대여거치대, 반납거치대 제거
df.drop(columns=['자전거번호', '대여거치대', '반납거치대'], inplace=True)
df.info()
#자료형 확인/변경
# 자료형 확인
df.dtypes
print(df['대여 대여소번호'].nunique())
print(df['반납대여소번호'].nunique())
# 카테고리형으로 변경: 대여 대여소번호, 반납대여소번호
df['대여 대여소번호'] = df['대여 대여소번호'].astype('category')
df['반납대여소번호'] = df['반납대여소번호'].astype('category')
df.dtypes
# 메모리 용량 확인
df.info()
# datetime형으로 변경 : 대여일시,반납일시
df['대여일시'] = pd.to_datetime(df['대여일시'])
# error가 발생하는 데이터 null로 처리하는 옵션 적용
df['반납일시'] = pd.to_datetime(df['반납일시'], errors='coerce')
# 자료형 변경 확인
df.dtypes
## 결측치 확인/처리
# 결측치 확인
df.isnull().sum()
# 결측치 제거
df.dropna(inplace=True)
# 결측치 확인
df.isnull().sum()
전처리 작업을 통해 나에게 필요한 데이터프레임을 구축하였다.
[51차시] 일별 이용현황 분석
대여날짜 컬럼 추가
df['대여날짜'] = df['대여일시'].dt.date
대여날짜 별 대여 건수
# 대여날짜 별 대여건수 추출
df_count = df.groupby('대여날짜').대여일시.count().to_frame()
# 대여날짜 별 대여건수 시각화 & 컬럼명 변경
df_count.columns=['대여건수']
#시각화
plt.plot(df_count.index, df_count.values)
plt.title('서울시 공공자전거 대여 날짜 별 대여건수')
plt.show()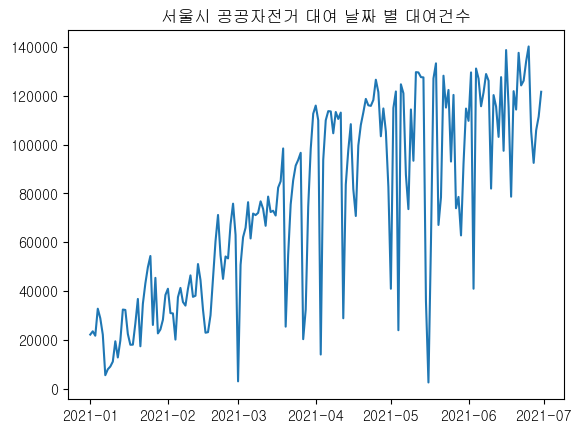
대여날짜별로 대여건수가 점점 증가하는 추세임을 알 수 있다.
초반에는 겨울이기 때문에 대여건수가 적고,
날씨가 풀려감에 따라 대여건수가 증가한다고 해석할 수 있다.
대여날짜 별 이용시간
# 대여날짜 별 이용시간 추출
df_time = df.groupby('대여날짜')['이용시간'].sum().to_frame()
# 대여날짜 별 이용시간 시각화
plt.plot(df_time.index, df_time['이용시간'])
plt.title('서울시 공공자전거 대여 날짜 별 이용시간')
plt.show()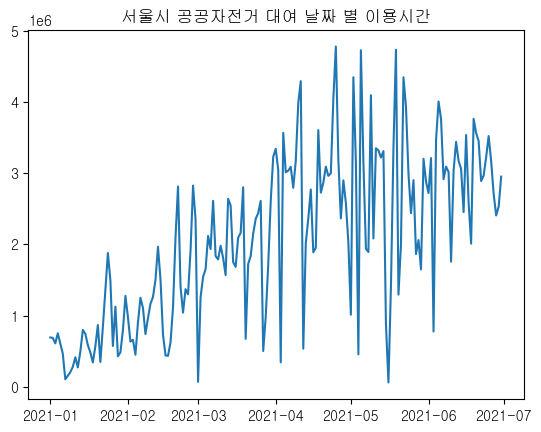
날씨가 좋은 봄에 비해 여름이 비교적 이용시간이 적고,
겨울에는 이용시간이 현저히 떨어짐을 알 수 있다.
대여날짜 별 이용 거리
# 대여날짜 별 이용거리 추출
df_distance = df.groupby('대여날짜')['이용거리'].sum().to_frame()
# 대여날짜 별 이용거리 시각화
plt.plot(df_distance.index, df_distance['이용거리'])
plt.title('서울시 공공자전거 대여 날짜 별 이용거리')
plt.show()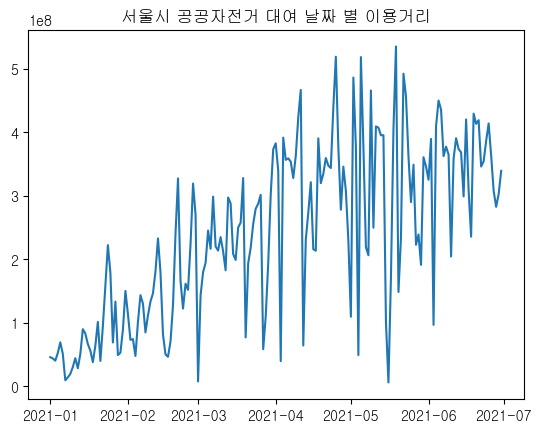
이용 시간과 비슷한 양상을 보이는 것을 확인할 수 있다.
데이터프레임 합치기
df_date = pd.concat([df_time,df_distance,df_count], axis=1)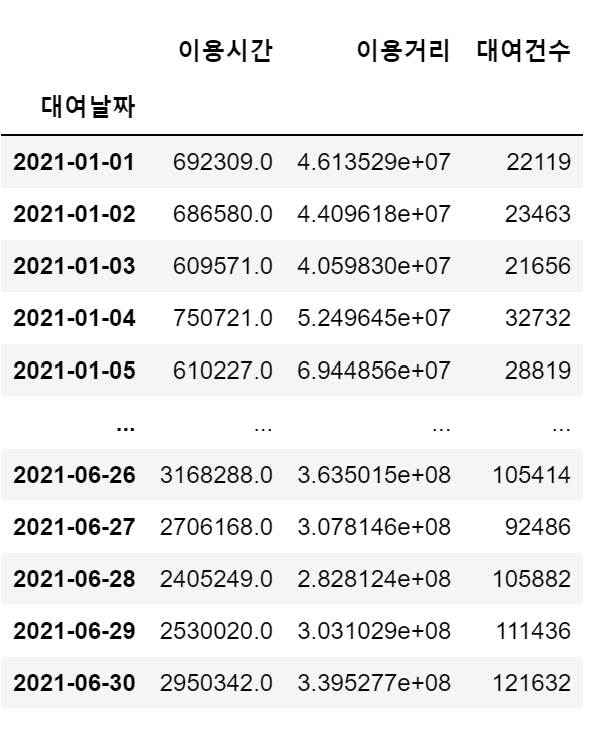
[52차시] 시간대별 대여/반납 현황 분석
대여시간, 반납시간 컬럼 추가
df['대여시간'] = df['대여일시'].dt.hour
df['반납시간'] = df['반납일시'].dt.hour
df.dtypes
시간대별 대여/반납 현황
# 시간대별 대여현황
s_rental = df['대여시간'].value_counts()
s_rental
# 시간대별 반납현황
s_return = df['반납시간'].value_counts()
s_return
시각화
# 시간 순 정렬
s_rental = s_rental.sort_index()
s_rental
# 시간대별 공공자전거 대여건수 시각화
x = s_rental.index
y = s_rental.values
plt.bar(x,y)
plt.title('서울시 공공자전거 시간대별 대여 건수')
plt.xlabel('대여시간')
plt.ylabel('대여건수')
plt.show()
# 시간 순 정렬
s_return = s_return.sort_index()
# 시간대별 공공자전거 반납건수 시각화
x = s_return.index
y = s_return.values
plt.bar(x,y,color='pink')
plt.title('서울시 공공자전거 시간대별 반납 건수')
plt.xlabel('반납시간')
plt.ylabel('반납건수')
plt.show()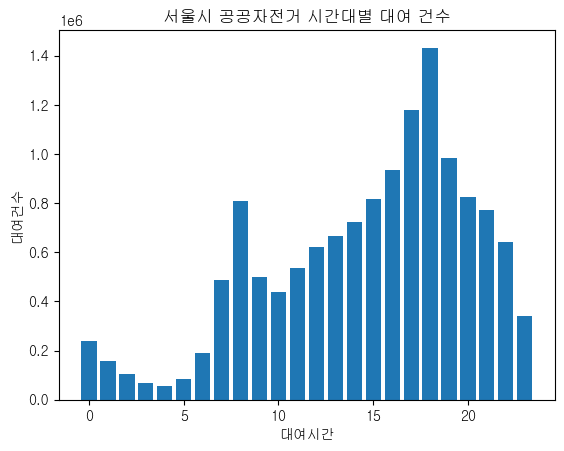
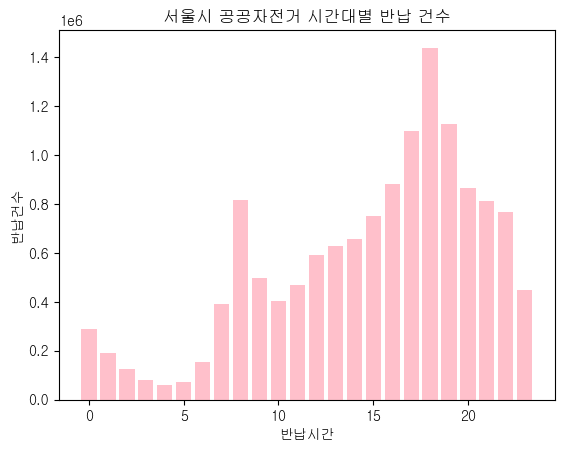
아침시간대와 저녁시간대(=출퇴근/등하교 시간)에 대여 및 반납 건수가 많은 것을 확인할 수 있다.
[53차시] 대여소별 대여/반납 현황 분석
대여소 현황
# 대여 대여소번호 갯수
df['대여 대여소번호']
# 반납대여소번호 갯수
df['반납대여소번호']
# 반납대여소에는 00437로 들어가있다.
df[df['대여 대여소번호'] == 437]
# 반납대여소 번호 처리 (str형으로 변환)
df['반납대여소번호'] = df['반납대여소번호'].astype('str')
# 반납대여소 번호 처리 (왼쪽의 '0' 제거)
df['반납대여소번호'] = df['반납대여소번호'].str.lstrip('0')
# 반납대여소 번호 처리 (int형으로 변환)
df['반납대여소번호'] = df['반납대여소번호'].astype('int')
# 반납대여소 번호 처리 (category형으로 변환)
df['반납대여소번호'] = df['반납대여소번호'].astype('category')
df.dtypes
# 대여 대여소번호와 데이터 개수와 형태가 같아짐
df['반납대여소번호']
## 대여건수가 가장 많은 대여소 best10
# value_counts
df[['대여 대여소번호','대여 대여소명']].value_counts()[:10].to_frame()
## 반납건수가 가장 많은 대여소 best10
# value_counts
df[['반납대여소번호','반납대여소명']].value_counts()[:10].to_frame()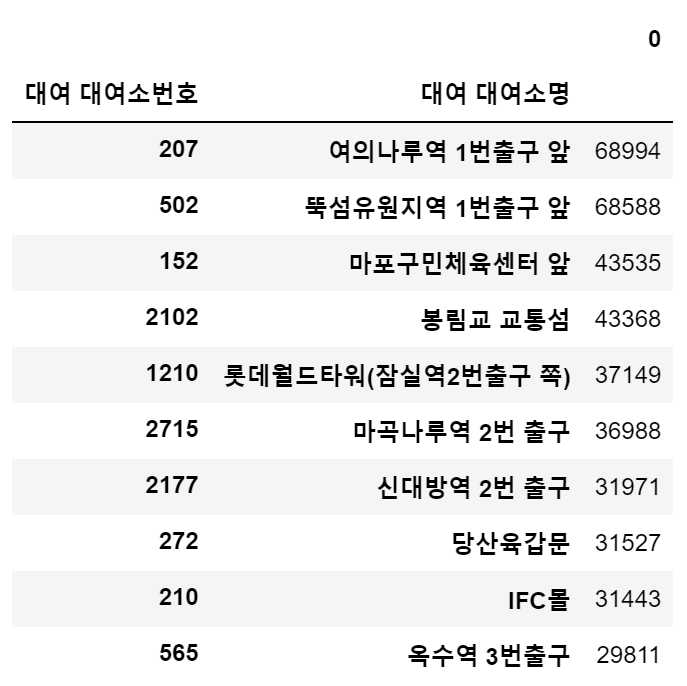
여의나루역 1번출구 앞에서 대여가 가장 많이 이루어지는 것을 확인할 수 있다.
해당 대여소에 대해 좀 더 자세히 살펴보자.
여의나루역 1번출구 앞 대여소 이용현황
## 서브셋 만들기
df_207 = df[df['대여 대여소번호']==207]
## 반납 현황
# value_counts
df_207[['반납대여소번호','반납대여소명']].value_counts().to_frame()
## 요일별 대여현황
#요일컬럼 추가 : strftime('%a')
#경고창은 무시해도 됨
df_207['대여요일'] = df_207['대여일시'].dt.strftime('%a')
# value_counts
df_207['대여요일'].value_counts()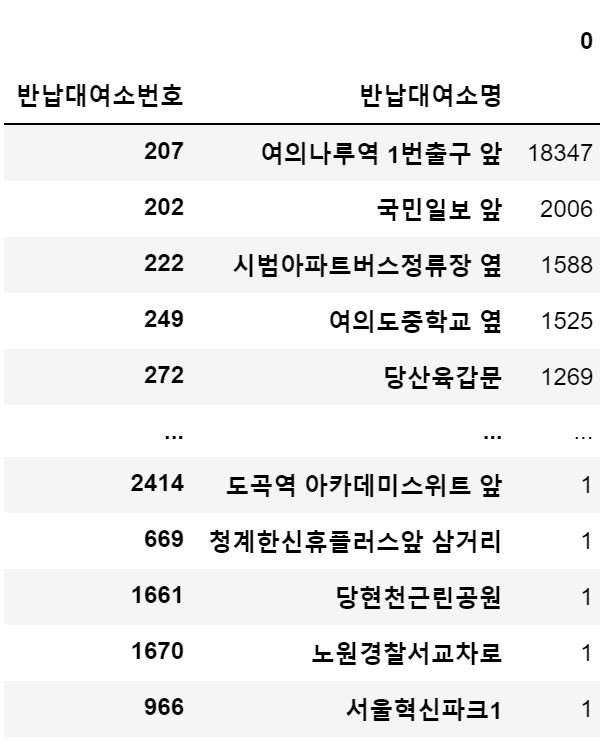
여의나루역에서 공공자전거를 대여한 사람들은 보통 같은 대여소에 자전거를 반납하는 것을 확인할 수 있다.
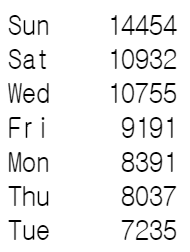
여의나루역의 요일별 대여현황을 살펴보면 주말이 가장 많은 것을 알 수 있다.
여의나루역에서는 위에서 추측한 출퇴근시간의 이용이 아닌
주말의 휴가 및 오락의 용도로 자전거를 사용할 수 있음을 알 수 있다.
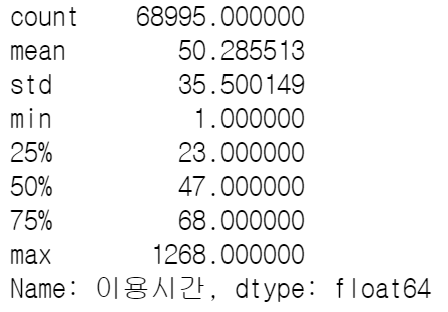
이용시간 통계
df_207['이용시간'].describe()
# 전체데이터 이용시간 평균
df['이용시간'].mean()강의에서는 이용시간의 평균, 최대값, 최소값을 각각 구하셨는데
describe를 이용하면 한 눈에 볼 수 있다.
[54차시] 데이터 수집 및 전처리
📖 함수 정리
- 특정 문자열이 포함되어있는지 확인: .str.contains(문자열)
- 중복 행 제거: .drop_duplicates()
- 구분기호를 기준으로 문자열 나누기: .str.split(' ')
- 높은순 보기: df.nlargest(갯수, 컬럼명)
import pandas as pd
import matplotlib.pyplot as plt
# 그래프를 노트북 안에 그리기 위해 설정
%matplotlib inline
# 필요한 패키지와 라이브러리 가져온다.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
# 폰트 지정하기
plt.rcParams['font.family'] = 'NanumBarunGothic'데이터 수집
# 1. 데이터 프레임 생성
df = pd.read_csv('data/생필품 농수축산물 가격 정보(2021년1월_6월).csv', encoding='cp949')
# 2. 결측치 확인
df.isnull().sum()
# 3. 자료형 확인
df.dtypes
데이터 확인
# 1. 컬럼별 데이터 확인
df['시장/마트 번호'].nunique()
# 2. 시장/마트 목록
df['시장/마트 이름'].nunique()
df['시장/마트 이름'].unique()
df_market = df[['시장/마트 번호','시장/마트 이름','자치구 이름','시장유형 구분(시장/마트) 이름']].drop_duplicates()
# 자치구 별 시장/마트 갯수
df_market['자치구 이름'].value_counts()
# 자치구 이름으로 시장/마트 확인
df_market[df_market['자치구 이름']=='중구']
# 3. 품목 목록
# 품목 목록
df_items =df[['품목 번호','품목 이름']].drop_duplicates()
df_items = df_items.sort_values('품목 이름')
# 품목 이름 (30개씩 확인)
df_items[:30]
df_items[30:60]
df_items[60:]
## 4. 자치구 목록
df_gu = df[['자치구 코드','자치구 이름']].drop_duplicates()
df_gu.shape
## 5. 시장 유형
df_gubun = df[['시장유형 구분(시장/마트) 코드','시장유형 구분(시장/마트) 이름']].drop_duplicates()
[55차시] 구별/마트별 삼겹살 가격 분석
1. 삼겹살 데이터
# 삼겹살이 포함되어있는 데이터 & 2021-06 데이터 이용 & 600g
df_sam = df[ (df['품목 이름'].str.contains('삼겹살')) & (df['년도-월']=='2021-06') & (df['실판매규격'].str.contains('600g')) ]
# 삼겹살 600g의 평균 가격은?
df_sam['가격(원)'].mean()
# 삼겹살 600g의 최고 가격은?
df_sam['가격(원)'].max()
# 삼겹살 600g의 최저 가격은?
df_sam['가격(원)'].min()
df_sam[df_sam['가격(원)']<5000]
2. 우리동네 삼겹살 가격
gu = input('구이름:')
# 우리구 삼겹살 가격
df_sam_gu = df_sam[df_sam['자치구 이름']==gu][['시장/마트 이름','품목 이름','실판매규격','가격(원)']].drop_duplicates()
# 시각화
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
x = df_sam_gu['시장/마트 이름']
y = df_sam_gu['가격(원)']
plt.scatter(x,y)
plt.title(gu+' 삼겹살 가격')
plt.grid(True)
plt.show()시각화 과정에서 한글이 깨지는 문제가 발생하여 코드를 추가하였다.
[참고 링크]
[Python] Matplotlib, Shap Plot 한글 깨짐 해결
📚 Matplotlib & Shap plot 한글 깨짐 문제 • python에서 시각화를 할 때 한글이 깨지는 경우가 종종 발생한다. 여러 가지 해결 방법이 있지만, 내 로컬 환경에서 가장 간단하게 문제를 해결할 수 있었
yeong-jin-data-blog.tistory.com
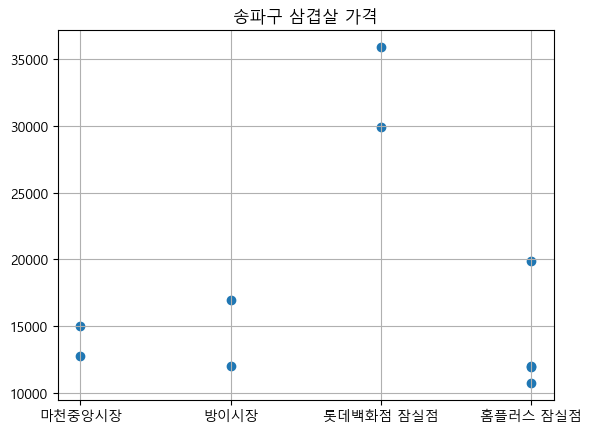
롯데백화점 잠실점의 삼겹살 가격이 비교적 높은 것을 확인할 수 있다.
3. 마트 지점별 삼겹살 가격
mart = input('시장/마트이름:')
# 마트 지점별 삼겹살 가격
df_sam_mart = df_sam[df_sam['시장/마트 이름'].str.contains(mart)][['시장/마트 이름','품목 이름','실판매규격','가격(원)']].drop_duplicates()
# 시각화
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
x = df_sam_mart['시장/마트 이름']
y = df_sam_mart['가격(원)']
plt.scatter(x,y)
plt.grid(True)
plt.title(mart+ ' 삼겹살 가격')
plt.xticks(rotation=45)
plt.show()
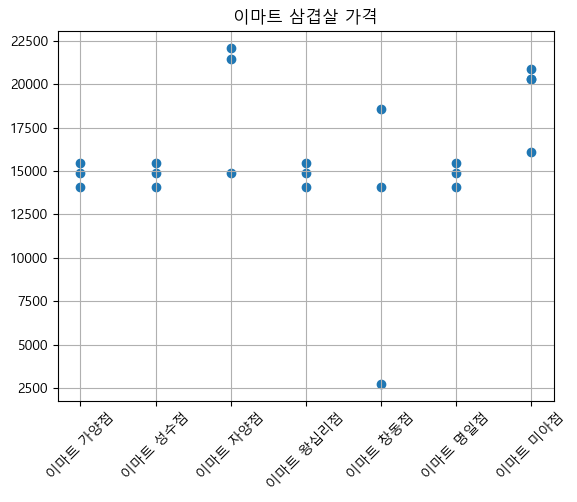
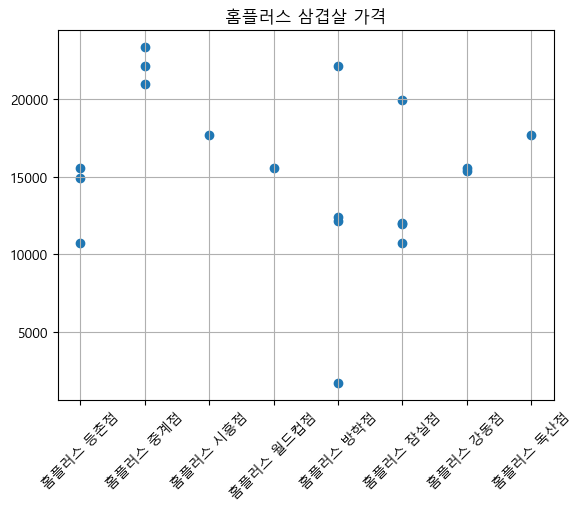
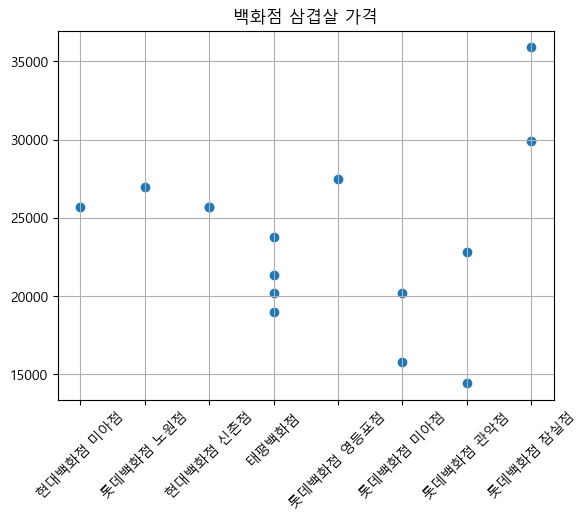
이마트는 삼겹살의 평균 가격이 15000원인 것을 확인할 수 있다.
이에 비해 홈플러스와 백화점은 가격의 편차가 큰 편이다.
백화점 삼겹살의 경우 가격대가 비교적 높게 형성되어있는 것을 확인할 수 있다.
[56차시] 구별/마트별 달걀 가격 분석
1. 달걀 데이터
# 2021-06 데이터 이용
df_egg = df[(df['품목 이름'].str.contains('달걀')) & (df['년도-월']=='2021-06') & (df['실판매규격'].str.contains('30개')) & (df['가격(원)']>0)]
# 달걀 30구 평균 가격
df_egg['가격(원)'].mean()
# 달걀 최고 가격
df_egg['가격(원)'].max()
df_egg[df_egg['가격(원)']>20000]
# 달걀 최저 가격
df_egg['가격(원)'].min()
df_egg[df_egg['가격(원)'] < 6000]
2. 우리동네 달걀 가격
gu = input('구이름:')
# 우리구 달걀 가격
df_egg_gu = df_egg[df_egg['자치구 이름']==gu][['시장/마트 이름','품목 이름','실판매규격','가격(원)']].drop_duplicates()
# 시각화
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
#df_egg_gu.sort_values('가격(원)')
x = df_egg_gu['시장/마트 이름']
y = df_egg_gu['가격(원)']
plt.scatter(x,y)
plt.grid(True)
plt.title(gu+' 달걀가격(30구)')
plt.xticks(rotation=45)
plt.show()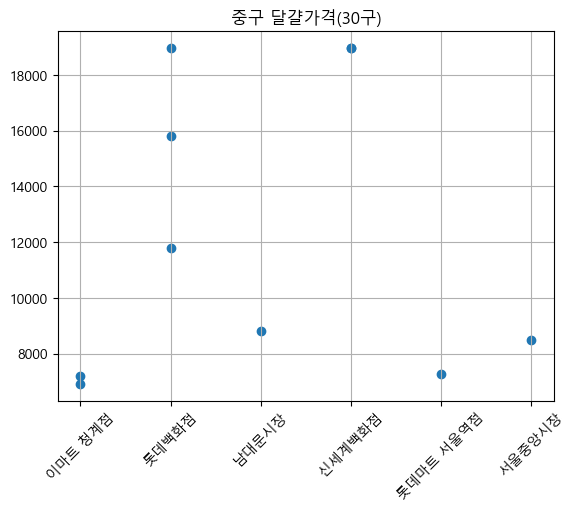
중구의 달걀 가격을 살펴보면 백화점에서 가격이 높고 시장이나 마트는 가격대가 낮은 것을 찾을 수 있다.
흥미로운 것은 시장보다 대형마트의 달걀 가격이 더 저렴하다는 것이다.
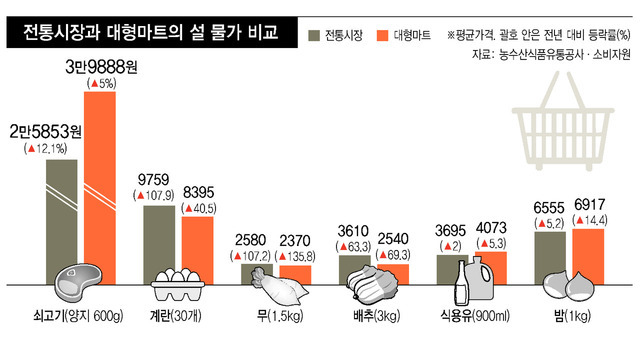
%EC%84%A4%20%EC%83%81%EC%B0%A8%EB%A6%BC%20%EC%87%A0%EA%B3%A0%EA%B8%B0%EB%8A%94%20%EC%A0%84%ED%86%B5%EC%8B%9C%EC%9E%A5%2C%20%EA%B
%EB%86%8D%EC%88%98%EC%82%B0%EB%AC%BC%EC%9C%A0%ED%86%B5%EA%B3%B5%EC%82%AC%2C%20%ED%95%9C%EA%B5%AD%EC%86%8C%EB%B9%84%EC%9E%90%EC%9B%90%20%EB%93%B1%20%EC%84%A4%20%EC%83%81%EC%B0%A8%EB%A6%BC%20%EB%B9%84%EC%9A%A9%20%EA%B3%B5%EA%B0%9C%20%20%EC%9E%AC%EB%9E%98%EC%
www.hani.co.kr
실제로 이와 유사한 기사를 찾을 수 있었다.
3. 마트 지점별 달걀 가격
gu = input('마트이름:')
# 마트 지점별 달걀 가격
df_egg_mart = df_egg[df_egg['시장/마트 이름'].str.contains(gu)][['시장/마트 이름','품목 이름','실판매규격','가격(원)']].drop_duplicates()
# 시각화
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Malgun Gothic'
x = df_egg_mart['시장/마트 이름']
y = df_egg_mart['가격(원)']
plt.scatter(x,y)
plt.xticks(rotation=45)
plt.grid(True)
plt.title(gu+' 달걀가격(30구)')
plt.show()
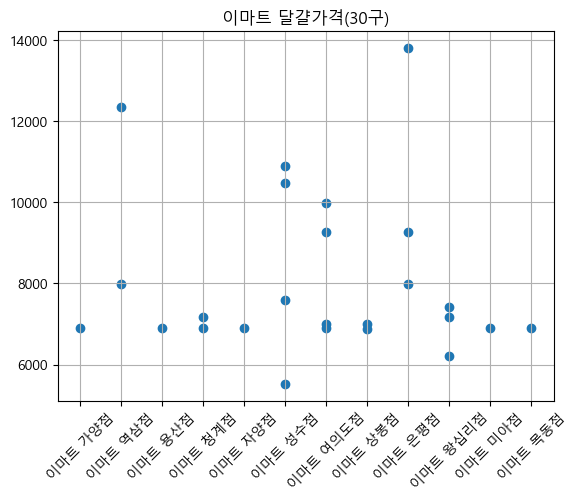
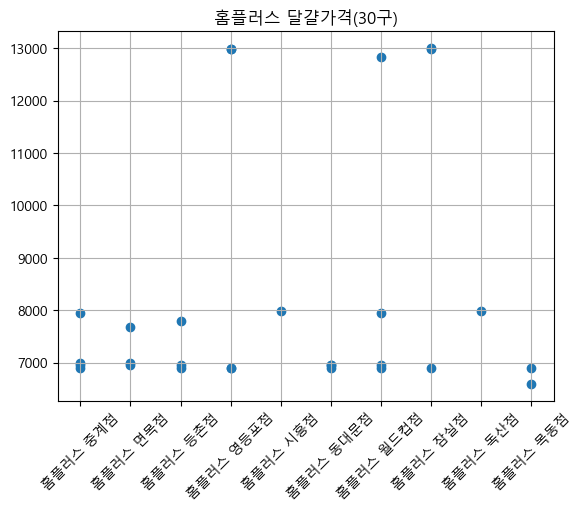

달걀 가격 비교 결과 삼겹살과는 약간 다른 양상을 보였다.
가격의 편차가 삼겹살에 비해 적은 편이고 백화점을 제외하고는 평균값도 비슷한 것을 확인할 수 있다.
[57차시] 데이터 수집 및 전처리
import pandas as pd
# 그래프를 노트북 안에 그리기 위해 설정
%matplotlib inline
# 필요한 패키지와 라이브러리 가져온다.
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
# 폰트 지정하기
plt.rcParams['font.family'] = 'gulim'
1. 데이터 확인 및 전처리
df = pd.read_csv('data/서울시 지하철 호선별 역별 시간대별 승하차 인원 정보.csv', encoding='cp949')
## 1. 데이터 크기
df.shape
## 2. 결측치 확인
df.isnull().sum()
## 3. 컬럼별 데이터 확인
# 사용월
df['사용월'].unique()
# 호선명
df['호선명'].unique()
## 4. 데이터 타입 확인 및 변경
df.dtypes
df['사용월'] = df['사용월'].astype('str')
df.dtypes
## 5. 불필요한 컬럼 삭제
df.drop(columns=['작업일자'], inplace=True)
## 6. 승차/하차 테이블 분리
# 1. 승차 테이블 만들기
# 공통 컬럼 (사용월, 호선명, 지하철역)
df1 = df.iloc[:,:3]
# 승차 컬럼만 가져오기
df2 = df.iloc[:,3::2]
# 컬럼명 변경 (승차인원 제거)
df2.columns = df2.columns.str.split(' ').str[0]
# 공통컬럼과 승차컬럼 연결하기
df_in = pd.concat([df1,df2], axis=1)
## 7. 하차 테이블 만들기
# 공통 컬럼
df1 = df.iloc[:,:3]
# 하차 컬럼만 가져오기
df2 = df.iloc[:,4::2]
# 컬럼명 변경 (하차인원 제거)
df2.columns = df2.columns.str.split(' ').str[0]
# 공통컬럼과 하차컬럼 연결하기
df_out = pd.concat([df1,df2], axis=1)[58차시] 출퇴근시간 승하차분석
2. 출퇴근시간 역별 승하차인원 분석
# 최근 월을 기준으로 한 승하차 데이터프레임 생성
df_in_202108 = df_in[df_in['사용월']=='202108']
df_out_202108 = df_out[df_out['사용월']=='202108']
# 출근시간에 가장 많은 사람이 승차하는 역은 어디일까? (08시-09시)
df_in_202108.nlargest(10,'08시-09시')[['지하철역','08시-09시']]
# 출근시간에 가장 많은 사람이 하차하는 역은 어디일까?(09시-10시)
df_out_202108.nlargest(10,'09시-10시')[['지하철역','09시-10시']]
# 퇴근시간에 가장 많은 사람이 승차하는 역은 어디일까?(18시-19시)
df_in_202108.nlargest(10,'18시-19시')[['지하철역','18시-19시']]
# 퇴근시간에 가장 많은 사람이 하차하는 역은 어디일까?(19시-20시)
df_out_202108.nlargest(10,'19시-20시')[['지하철역','19시-20시']]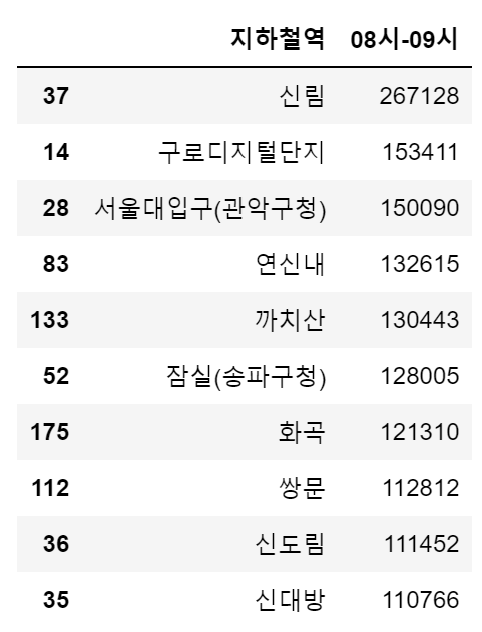
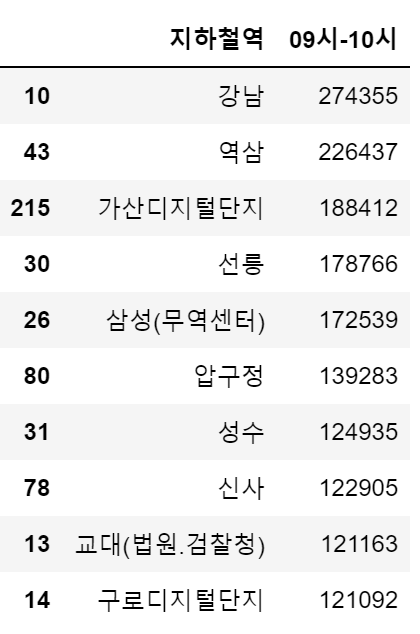
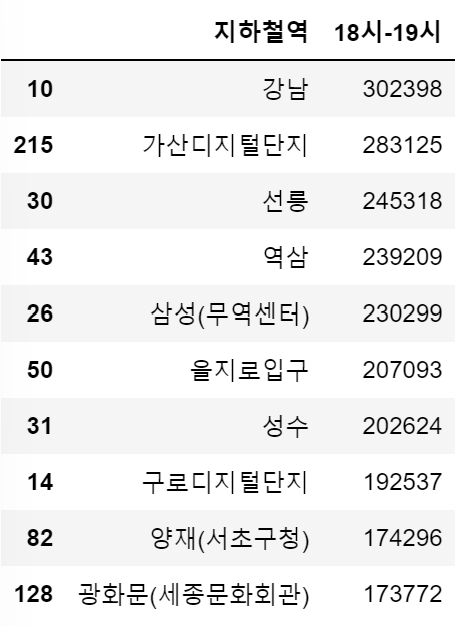
분석결과 출근시간에는 신림 승차, 강남 하차 / 퇴근시간에는 강남 승차, 신림 하차인원이 많은 것을 확인할 수 있다.
[59차시] 지하철 역별/시간대별 승하차 현황 분석
3. 강남역의 최근 시간대별 승하차정보 분석
## 1. 강남역의 최근 승차정보 분석
# 강남역의 최근 승차 데이터 불러오기
df_gangnam_in = df_in_202108[df_in_202108['지하철역']=='강남'].iloc[:,3:]
df_gangnam_in
# melt
df_gangnam_in = df_gangnam_in.melt()
# 컬럼명 변경
df_gangnam_in.columns=['시간대','승차건수']
df_gangnam_in.sort_values('승차건수')
# 시간대별 승차인원 시각화하기
df_gangnam_in
plt.figure(figsize=(10,7))
plt.barh(df_gangnam_in['시간대'], df_gangnam_in['승차건수'])
plt.show()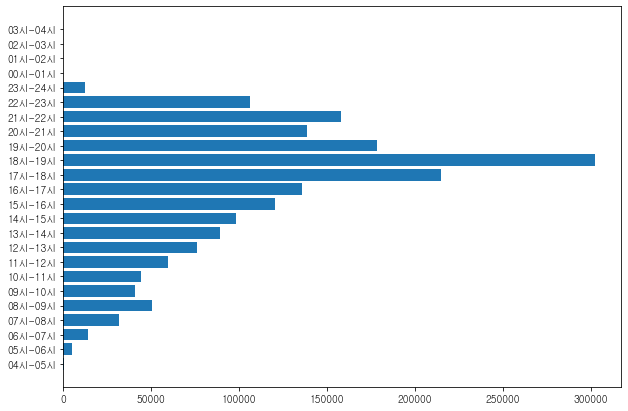
퇴근시간대에 승차 인원이 많다.
## 2. 강남역의 최근 하차 정보 분석
# 강남역의 최근 하차 데이터 불러오기
df_gangnam_out = df_out_202108[df_out_202108['지하철역']=='강남'].iloc[:,3:]
df_gangnam_out
# melt
df_gangnam_out = df_gangnam_out.melt()
# 컬럼명 변경
df_gangnam_out.columns=['시간대','하차건수']
df_gangnam_out.sort_values('하차건수')
# 시간대별 승차인원 시각화하기
df_gangnam_out
plt.figure(figsize=(10,7))
plt.barh(df_gangnam_out['시간대'], df_gangnam_out['하차건수'])
plt.show()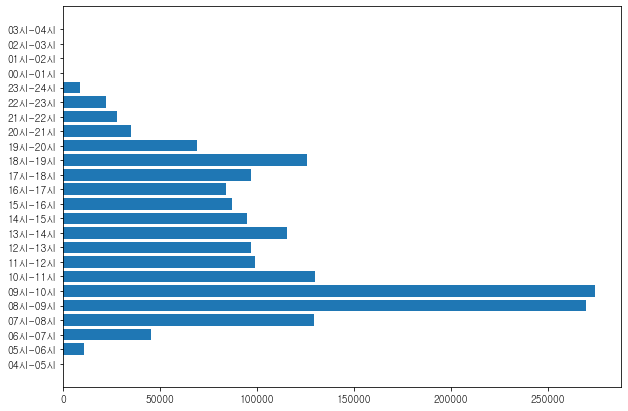
출근시간대에 하차 인원이 많다.
4. 지하철 시간대별, 역별 이용현황 분석
1. 시간대별 승차 현황
## 1. 승차정보 집계 데이터 만들기
# df_in_202108카피하여 사용하기
df_in_202108_agg = df_in_202108.copy()
# 인덱스 변경('지하철역')
df_in_202108_agg.index = df_in_202108_agg['지하철역']
# 컬럼 삭제('사용월','호선명','지하철역')
df_in_202108_agg.drop(columns= ['사용월','호선명','지하철역'], inplace=True)
# 행,열 합계
df_in_202108_agg.loc['sum'] = df_in_202108_agg.apply('sum', axis=0)
df_in_202108_agg['sum'] = df_in_202108_agg.apply('sum',axis=1)
## 2. 시간대별 승차건수
s_in = df_in_202108_agg.loc['sum'][:-1].sort_values()
s_in = s_in.sort_index()
x = s_in.index
y = s_in.values
plt.bar(x,y)
plt.xticks(rotation=90)
plt.show()
## 3. 지하철역별 승차건수
df_in_202108_agg['sum'][:-1].sort_values(ascending=False).to_frame()
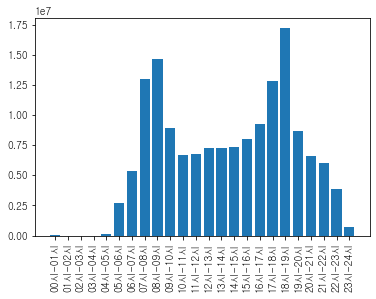
시간대별 승차건수를 살펴보면 출퇴근시간이 가장 많은 것을 알 수 있고,
지하철역별 승차건수를 살펴보면 강남, 잠실, 신림 순서로 많은 것을 알 수 있다.
2. 시간대별 하차 현황
## 1. 하차정보 집계 테이블 만들기
# df_out_202108카피하여 사용하기
df_out_202108_agg = df_out_202108.copy()
# 인덱스 변경('지하철역')
df_out_202108_agg.index = df_out_202108_agg['지하철역']
# 행,열 합계
df_out_202108_agg.loc['sum'] = df_out_202108_agg.apply('sum', axis=0)
df_out_202108_agg['sum'] = df_out_202108_agg.apply('sum', axis=1)
## 2. 시간대별 하차 건수
df_out_202108_agg.loc['sum'].sort_values()
## 3. 지하철역별 하차건수
df_out_202108_agg['sum'][:-1].sort_values(ascending=False)[:10].to_frame()
위와 동일한 결과를 확인할 수 있다.
[60차시] 파이썬 데이터 시각화소개
데이터 시각화란?
- 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달되는 과정
- 데이터 시각화의 목적은 graph를 통해 정보를 명확하고 효과적으로 전달하는 것
데이터 시각화의 필요성
텍스트 기반의 데이터를 분석하고 이해하는 것도 중요하지만 텍스트 기반의 데이터를 사람의 눈으로 파악하는 데에는 한계가 있다.
데이터를 시각화하면
- 많은 데이터를 한눈에 파악할 수 있다.
- 데이터의 변화, 데이터 사이의 관계 등을 쉽게 볼 수 있어 데이터를 깊이 있게 이해할 수 있다.
- 수치로만 파악하기 힘든 패턴이나 새로운 정보를 발견할 수 있다.
데이터 시각화 사례 및 해석
[현상파악]
- 나폴레옹 진군 맵 (1812년)
[원인도출]
- 콜레라 발병 맵(1854년)
- 나이팅게일 로즈 다이어그램
[추세파악/예측]
→ 인사이트 도출
목적에 따른 그래프의 종류
- 시간 시각화
- 비교 시각화
- 공간 시각화
- 비율 시각화
- 데이터 관계 시각화
- 분포 시각화
[61차시] 기본 그래프 그리기
라이브러리 임포트
- matplotlib의 pyplot 모듈 사용
- 관용적으로 plt라는 별칭 사용
import matplotlib.pyplot as plt
기본 그래프 그리기
- plt.plot(data)
- plot에 데이터를 전달하여 그린다.
- y축 데이터로 그리기
- 1차원 리스트, 튜플, 시리즈 데이터를 전달하여 그린다.
- x축은 데이터의 인덱스로 자동 지정된다.
- x축, y축 데이터로 그리기
- x축과 y축 데이터의 길이가 같아야 한다.
# 시리즈 데이터의 인덱스 변경하기 : index = [10,20,30,40,50]
ss = pd.Series([1,5,3,9,7], index=[10,20,30,40,50])[62차시] 목적에 따른 여러가지 그래프
| 시각화 | 종류 | 코드 |
| 시간 시각화 | 선그래프 | plt.plot() |
| 수량비교 시각화 | 막대그래프 가로 막대 그래프 |
plt.bar() plt.barh() |
| 비율 시각화 | 파이차트 | plt.pie() |
| 분포 시각화 | 히스토그램 상자수염그래프 바이올린그래프 |
plt.hist() plt.boxplot() plt.violinplot() |
| 관계 시각화 | 산점도(scatter) | plt.scatter() |
[63차시] 한글폰트사용, 색상, 마커, 선
➡️ 그래프의 가독성을 높이고 보기좋게 꾸미기 위해 색상, 마커, 선의 스타일을 설정할 수 있다.
한글폰트 사용
# 한글폰트 지정
plt.rcParams['font.family'] = 'Malgun Gothic'
# 한글폰트 사용 시 -기호 깨지는 문제 해결
plt.rcParams['axes.unicode_minus']=False
색상
- color=색상
- 색상 이름을 사용한다. https://matplotlib.org/2.0.2/examples/color/named_colors.html
- 자주 사용되는 색깔은 약자를 사용할 수 있다.(blue:b, green:g, red:r, cyan:c, magenta:m, yellow:y, black:k, white:w)
- hex code(색상 코드)를 사용할 수 있다.
마커
- marker : 마커종류 (* . , o v ^ < > 1 2 3 4 s p * h H + x D d)
- markersize, ms : 마커사이즈
- markeredgecolor, mec : 마커 선 색깔
- markeredgewidth, mew : 마커 선 굵기
- markerfacecolor, mfc : 마커 내부 색깔
선
- linestyle(ls) : 선스타일
'-' solid line style
'--' dashed line style
'-.' dash-dot line style
':' dotted line style - linewidth(lw) : 선 굵기
※ 색상, 선, 마커는 조합도 가능하다.
plt.plot(x,y,'g*:', ms=10, mec='r', mfc='k', lw=3);
먼저 주피터 마크다운 목차인 nbextensions는 아래 글을 참고하여 새로운 노트북에 설치했다.
주피터 노트북 Nbextensions로 목차 정리
출처 : jenna.log 주피터 스크립트를 작성하면서 자동으로 목차와 앵커 만들 수 있는데, 방법은 매우 간단하다. 스크립트 창에 아래 코드를 그대로 입력해주면, 해당 기능을 구현해주는 Nbextensions를
yrohh.tistory.com
그런데 설치 후 파일이 열리지 않는 오류가 발생했다.

강의 화면과 내 설정 화면을 비교해보니

이 부분이 Diable로 되어있었다.
Enable로 변경하니 파일이 잘 열린다 😊👌
목차도 잘보이고!

오늘의 궁금한점 1
하나의 데이터프레임만 전체 출력할 수 있는 방법이 있을까? (품목 이름 데이터프레임만 전체 행을 출력하고 원본 데이터 프레임은 원래대로 ...으로 잘리게 표시되도록) 구글을 통해서는 모든 데이터프레임을 전체출력하는 방법만 찾을 수 있었다.
[Pandas] 5. 데이터프래임(DataFrame) 모든 행, 모든 열 출력하기
안녕하세요. 꽁냥이에요~ 크기가 큰 데이터를 Pandas 데이터프래임(DataFrame)에 넣으면 아래의 빨간색으로 표시한 것처럼 중간 부분은 잘려서 나오게 됩니다. 하지만 상황에 따라서 중간에 잘린 데
zephyrus1111.tistory.com
오늘의 궁금한점2
구별/마트별 달걀 가격 분석을 하다가 시장보다 대형마트의 달걀 가격이 더 낮다는 것을 확인했다.
이러한 가격 차이에 대한 인사이트를 찾기 위한 팁이 있는지 궁금하다.
[파트너간 상보적 학습 및 강의 내용 리뷰]
이번 시간에는 서로 해결하지 못한 부분을 공유하는 시간을 가졌다.
파트너분의 문제는 데이터 프레임에서 value_counts() 에러가 나는 것이었다.
내 코드에서는 잘 돌아가서 차이점을 확인해보니 파이썬 버전에 차이가 있었다.
파이썬을 함부로 업그레이드하면 파일들이 엉킬 위험이 있어서 강사님께 질문하기로했다.
나는 위 질문에 대해 이야기했다.
엑셀로 해당 데이터프레임을 다운로드 받으면 전체 데이터프레임을 편하게 볼 수 있다는 해결법을 얻을 수 있었다!
그래도 혹시 주피터 내부에 해당 기능이 있을 수 있으니 강사님께 질문을 드리기로 했다.

끄으읕!!!!
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 1주차 학습 일지 (0) | 2023.02.10 |
|---|---|
| [👩💻TIL 5일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.10 |
| [👩💻TIL 3일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.08 |
| [👩💻TIL 2일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.07 |
| [👩💻TIL 1일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.06 |



