
홍동이의 성장일기
[👩💻TIL 21일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
시계열 데이터 분석 with 파이썬
[섹션7] 고급 매핑 기술 구현
다각형으로 모양 만들기
Polygon(다각형): 각이 많은 도형
- Points: X및 Y좌표
- Direction: 경로의 방향
- Unique Identifier: 모양 ID



배경 지도




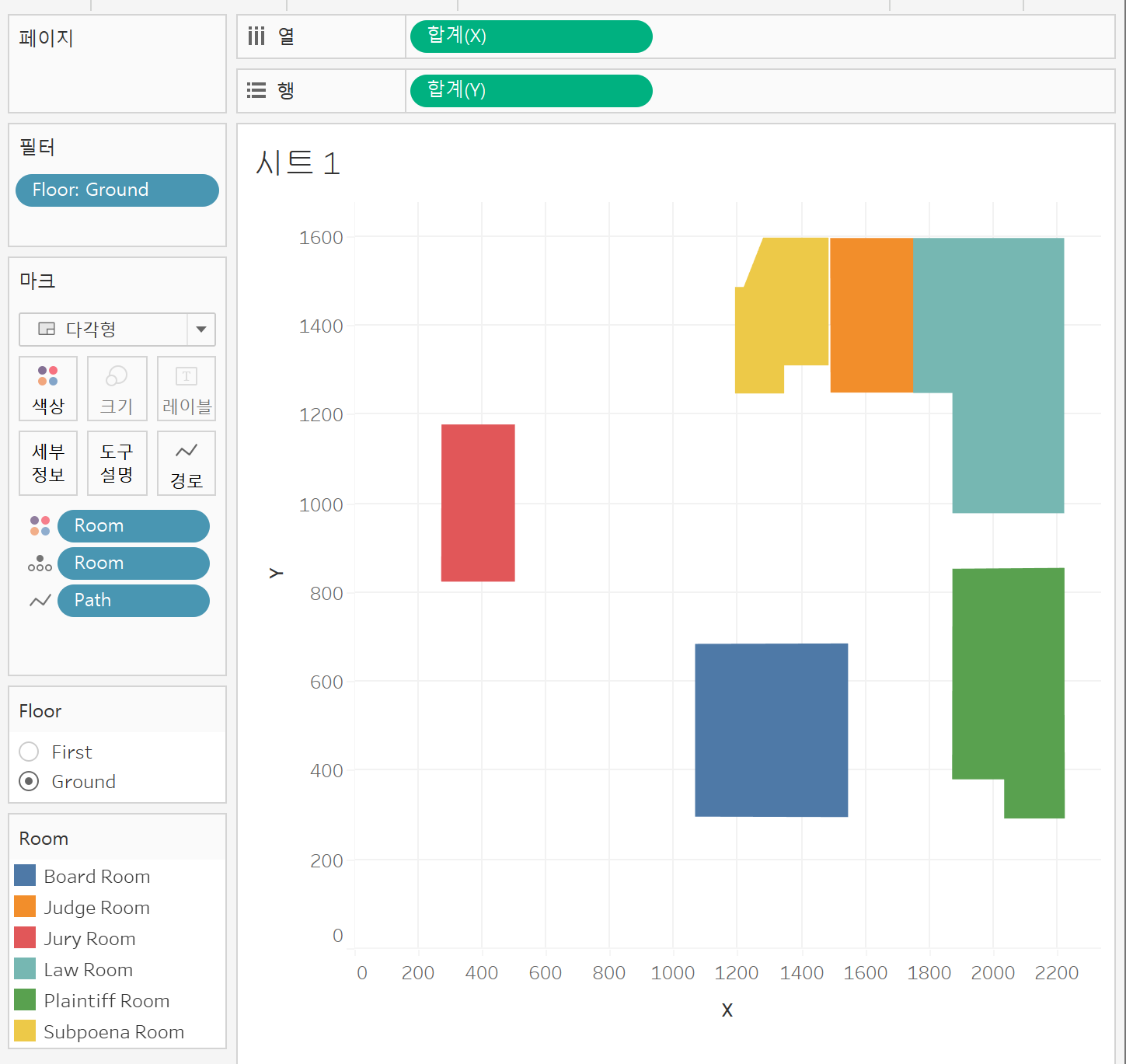
- 측정값으로 연결되어있는 Path를 차원으로 옮기기: 경로를 사용하여 계산을 수행하지 않을 것이라는 것을 알고 있기 때문에
- 필터로 1, 2층 구분
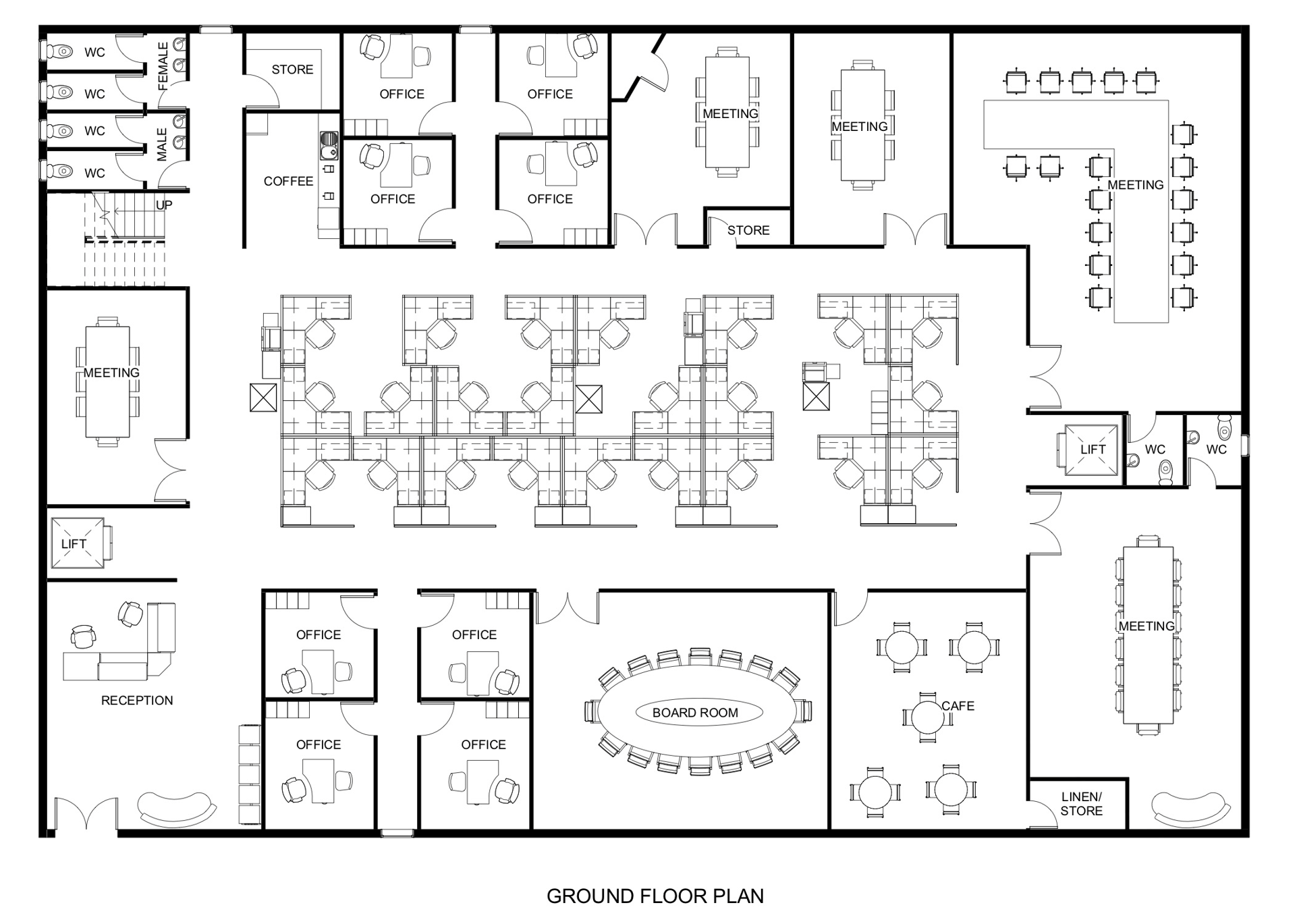
📍 배경 이미지 넣기


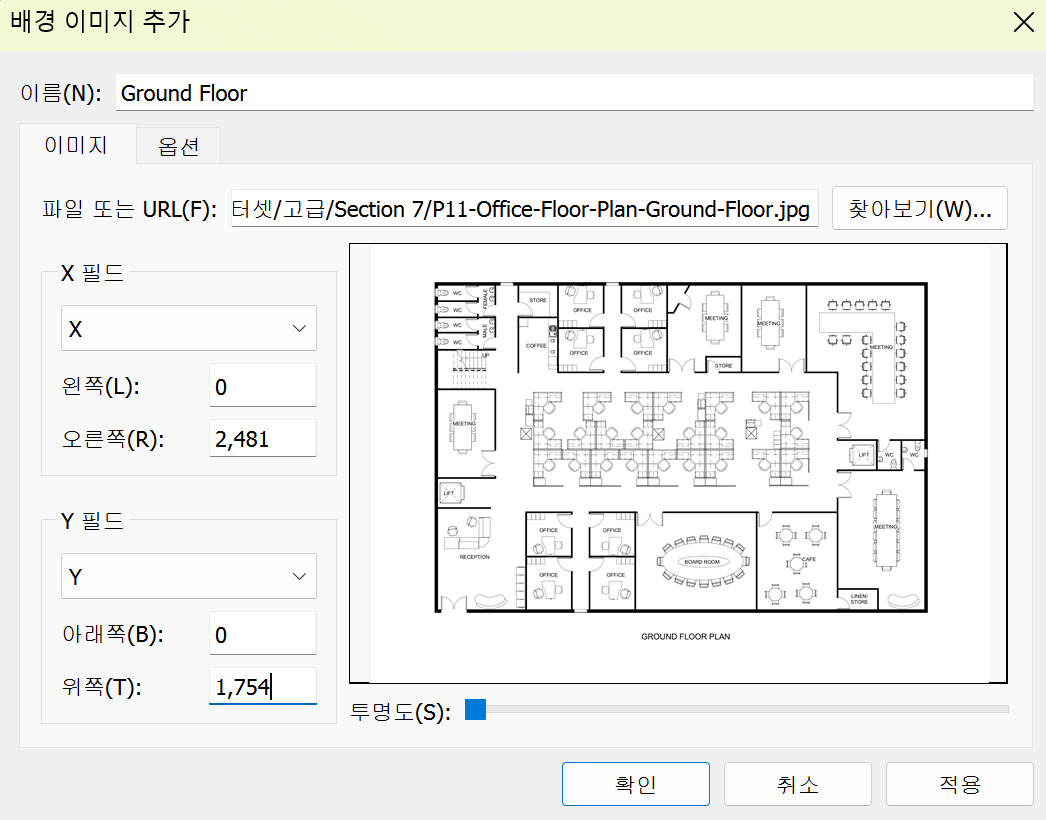


➡️ 시각화된 자료에 따르면 대부분의 룸이 예약이 꽉 찬 것을 볼 수 있다.
비즈니스 과제 해결하기
📍두 층 사이에 토글 스위치 추가하기


📍두번째 배경 이미지 추가하기
➡️ 기본 데이터 원본에서 계산된 필드 만들기




📍예약된 사용률과 실제 사용률 살펴보기


Tableau용 그리기 도구
Take Control of Your Tableau Workbooks - Power Tools for Tableau
Everyone knows that Tableau is the best way to analyze and visualize data. We at InterWorks are no exception. We love Tableau and use it every day! Not only that, we spend most of our time helping others use Tableau […]
powertoolsfortableau.com


지도의 사용자 지정 이미지



📍 아이콘 추가하는법


거리 계산




Mapbox로 지도 커스터마이즈 하기
Maps, geocoding, and navigation APIs & SDKs | Mapbox
Integrate custom live maps, location search, and turn-by-turn navigation into any mobile or web app with Mapbox APIs & SDKs. Get started for free.
www.mapbox.com
카드 정보를 기입하라길래 왠지 찜찜해서 안했다🤔
그래도 지도를 사용할일이 있을때 유용하게 사용될 기능일 것 같다.
[섹션2] 강의 Set up 및 Install
아나콘다 파이썬 배포판과 주피터 설치
📍 가상환경 생성 및 활성화
가상환경: 활성화하기만하면 사용할 수 있는 많은 라이브러리들의 특정 버전
➡️ tsa_course_env.yml을 다운로드 받은 후 conda env create -f tsa_course_emv.yml 입력
다운로드가 완료된 후 conda activate tsa_course을 입력하면 강좌의 환경 라이브러리가 활성화된다.

강좌 노트 실행: jupyter notebook
[섹션3] Numpy
Numpy 배열 - Part 1 & 2
Numpy: 배열로 저장된 대용량 데이터를 효율적으로 처리할 수 있는 수치 처리 라이브러리
- Numpy배열 만들기: 리스트를 직접 변환하여 배열을 만들 수 있다.
- 기본 제공 방법: 배열을 생성하는 다양한 기본 제공 방식이 있다.
- arange: 지정된 간격 내의 균등한 간격 값을 반환한다.
- zeros, ones: 0 또는 1의 배열을 생성한다.
- linspace: 지정된 간격 동안 균등한 간격의 숫자를 반환한다.
- eye: 고유 행렬을 작성한다.
- 랜덤: Numpy는 난수 배열을 만드는 많은 방법을 가지고 있다.
- rand: 지정된 모양의 배열을 만들고 0~1에 걸쳐 균일한 분포의 랜덤 표본으로 채운다.
- randn: 표준 정규 분포(=1)에서 표본을 반환한다. 균일한 rand와 달리 0에 가까운 값이 나타날 가능성이 높다.
- randint : 최소값(포함) ~ 최대값(제외)로 임의의 정수를 반환한다.
- seed: 동일한 랜덤 결과를 재현할 수 있도록 상태를 설정하는데 사용한다.
- 배열 특성 및 방법
- Reshape: 동일한 데이터가 포함된 배열을 새 모양으로 반환한다.
- max, min, argmax, argmin: 최대값 또는 최소값을 찾거나 인덱스 위치를 찾는다.
- Shape: 모양은 배열이 갖는 속성이다.
- dtype: 배열에 있는 개체의 데이터 유형을 가져올 수 있다.
Numpy 인덱싱과 선택
➡️ 배열에서 요소 또는 요소 그룹을 선택하는 방법에 대해 배웠다.
- 괄호 인덱싱 및 선택: 배열의 일부 요소를 선택하는 가장 간단한 방법은 파이썬 리스트와 매우 유사하다.
- 브로드캐스팅: Numpy 배열은 브로드캐스트 기능 때문에 일반 파이썬 리스트와 다르다. 리스트의 경우 크기와 모양이동일한 새 부분만 리스트에 재할당할 수 있다. Numpy 어레이를 사용하면 단일값을 더 큰 값 집합에 걸쳐 브로드캐스트 할 수 있다.
- 2차원 배열 인덱싱 (매트릭스): arr_2d[row][col] 또는 arr_2d[row,col]
- 추가 인덱싱 도움말
- 조건부 선택 : 불리언 배열을 필터로 원래 배열에 입력함으로써 조건부 선택을 수행할 수 있다.
Numpy 연산
- 산술
- 범용 배열 함수
- 배열에 대한 요약 통계
- 축 논리: 2차원 배열(매트릭스)을 사용할 때는 행과 열을 고려해야 한다. 배열에서 축 0은 수직 축(행)이고, 축 1은 수평 축(열)이다.
[섹션4] Pandas 개요
Pandas
- 패널데이터
- Numpy를 기본으로 한다
- 네임드 인덱스로 데이터를 직접 불러올 수 있다.
시리즈
➡️ 시리즈는 Numpy 배열과 매우 유사하다. Numpy 배열이 시리즈와 다른 점은 시리즈가 축 레이블을 가질 수 있다는 것이다. 즉, 숫자 위치가 아닌 레이블로 인덱싱할 수 있다. 또한 숫자 데이터를 보유할 필요가 없으며 임의의 파이썬 객체를 보유할 수 있다.
- 시리즈 만들기: 리스트, Numpy 배열 또는 딕셔너리를 시리즈로 변환할 수 있다.
- 인덱스 사용하기
- 두 정수와 함께 Pandas나 Numpy를 사용하여 산술 연산을 실행하는 경우 부동 소수점으로 나타난다.
데이터프레임 Part 1 & 2
➡️ 데이터프레임은 동일한 인덱스를 공유하기 위해 여러 개의 시리즈 객체가 결합된 것으로 생각할 수 있다.
- 선택 및 인덱싱
- 새로운 열 만들기
- 열 삭제하기: drop
- 행 선택하기
- loc: 행 위치 기반 사용
- iloc: 인덱스 위치 기반 사용
- 행 및 열의 부분 집합 선택
- 조건부 선택: 대괄호 표기법 사용
- 두가지 조건에 대해 | 및 &를 괄호와 함께 사용할 수 있다.
- 추가 인덱스 세부 정보
- 데이터 프레임 요약
- df.describe()는 숫자 열에 대한 요약 통계량을 제공한다.
- df.info 및 df.dtype은 모든 열의 데이터 유형을 표시한다.
Pandas로 결측 데이터 다루는 법
➡️ Pandas에서 결측 데이터를 처리하는 편리한 방법 살펴보기
- 제거: dropna
- axis =1: 열 제거
- thresh = n: 임계값 지정
- 채우기: fillna
Group By 연산
➡️ 그룹화를 통해 데이터의 행을 함께 그룹화하고 집계 함수를 호출할 수 있다.
- .groupby() 메서드를 사용하여 열 이름을 기준으로 행을 그룹화할 수 있다.
일반 연산
- 고유값에 대한 정보
- unique: 고유값
- nunique: 고유값의 수
- value_counts(): 각 고유값의 개수
- 데이터 선택
- 함수 적용하기
- 영구적으로 열 삭제하기: del
- 열 및 인덱스 이름 가져오기: columns, index
- 데이터 프레임 정렬: sort_values
데이터 입력과 출력
➡️ pd.read_ 메서드를 사용하여 다양한 파일 형식을 읽을 수 있다.
- CSV: 쉼표를 필드 구분 기호로 사용하는 텍스트 파일이다.
- 입력: pd.read_csv()
- 출력: .to_csv()
- Excel: 이미지 또는 매크로가 포함된 파일로 인해 메서드와 충돌을 일으킬 수 있으므로 수식이나 이미지가 아닌 데이터만 가져온다.
- 입력: pd.read_excel(sheet_name)
- 출력: .to_excel(sheet_name)
- HTML: HTML에서 테이블 탭을 읽을 수 있다.
- 입력: pd.read_html() → type: list
[섹션5] Pandas를 사용한 데이터 시각화
Pandas를 사용한 데이터 시각화
- 플롯 유형: df.plot._
df.plot(kind='area')와 같이 인수로 이름을 전달하여 특정 그래프를 호출할 수도 있다.- Histgrams: 데이터를 동일한 너비의 bin으로 나누고, 각 bin에 들어가는 값의 수를 표시하여 연속 데이터의 분포를 설명한다.
- 그래프 가장자리에 x축 및 y축 가져오기: autoscale → x, y, both, tight = True
- 그래프 테두리: edgecolor
- Barplots: 이산 데이터를 처리하고 종종 여러 변수를 반영한다는 점을 제외하면 히스토그램과 유사하다.
- 누적: stacked = True
- 가로: barh
- Line Plots: 둘 이상의 변수를 비교하는데 사용한다.
- 선굵기: lw
- Area Plots: 선 사이의 공간이 색상으로 강조된 누적된 선그림
- alpha: 0과 1사이의 투명도 값 전달
- 혼합 면적 그림: stacked = False
- Scatter Plots: 두 변수를 빠르게 비교하고 추세를 찾는데 유용한 도구
- colormaps: c를 사용하여 다른 열 값을 기준으로 각 마커에 색상을 지정할 수 있다. cmap을 사용하여 사용할 색상 맵을 지정한다.
- 다른 열을 기준으로 마커 크기를 나타낼 수 있다. s 매개 변수는 열 이름일 뿐만 아니라 배열이어야 한다.
- .apply(func)로 데이터에 함수를 적용할 수 있다.
- BoxPlots: 데이터를 평균에 대한 사분위수로 나누어 데이터의 분포를 설명한다.
- Groupby: 그룹을 기준으로 boxplots을 그리려면 먼저 열 목록을 정한 후 by = '열이름'을 적어준다.
- Kernal Density Estimation (KDE) Plot
- Hexagonal Bin Plot: 산점도 대신 이변량 데이터에 유용하다.
- pie
- Histgrams: 데이터를 동일한 너비의 bin으로 나누고, 각 bin에 들어가는 값의 수를 표시하여 연속 데이터의 분포를 설명한다.
Pandas로 만든 플롯의 사용자 정의
➡️ 축 레이블과 범례의 위치, 모양을 제어하는 방법을 배운다.
- 색, 너비, 선 스타일: .plot() 메서드는 선스타일, 색상, 너비 등을 제어할 수 있는 선택적 인수를 사용한다.

- 제목 및 축레이블 추가
- 객체 지향 플로팅: df.plot()을 호출하면 pandas는 matplotlib.axes.AxesSubplot을 반환한다.
- 범례 배치 플롯: 범례를 직접 배치하여 제어할 수 있고, 플롯 외부에 배치할 수도 있다. 이 작업은 .legend() 메서드를 통해 수행된다. (by 위치 코드, 위치 문자열)
- loc를 통해 전달된 값을 anchor 포인트로 처리하고, 두 값 튜플을 기반으로 x축과 y축을 따라 범례를 배치하는 두번째 인수인 bbox_to_anchor을 전달할 수 있다.
- 그림 외부에 범례 배치: 범례를 그림의 오른쪽 바깥쪽에 배치하려면 1보다 크거나 같은 값을 튜플의 첫번째 항목으로 전달한다.

✍️ 마무리하며


태블로를 마무리하고 수료증까지 받았다🙌 고급은 특히 더 어려웠는데 수료증까지 받고 나니 뿌듯하다. 이번에 들은 강의를 기반으로 오프라인 강의 때는 더 꼼꼼하게 태블로를 되짚어봐야겠다.
파이썬은 에이블런에서 들은 강의와 아직까지 결은 비슷하지만 기본단계를 벗어나서 그런지 진행 속도도 빠르고 내용도 좀 더 심화된 것 같다. 시계열 분석도 열심히 해봐야겠다💪
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌 본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 23일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.12 |
|---|---|
| [👩💻TIL 22일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.09 |
| [👩💻TIL 20일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.06 |
| [오류 해결] 태블로 오류 코드:6EA18A9E (0) | 2023.03.06 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지 (0) | 2023.03.04 |



