
홍동이의 성장일기
[👩💻TIL 30일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

- 차원을 하나 생성하고 서브 카테고리 붙이듯이 붙이기
- 이커머스는 데이터가 가장 많고 지저분하다. 아마존은 모든 것이 자동화되어있지만 너무 밑단까지 사람이 하면 트래킹이 불가능하다. NULL값이 많음
- 목요일에 프레젠테이션: 피드백 화, 수
보고서 피드백
- 목표 / 현황 중요, 납득만 시켜도 공격X
덱 하나로 줄이기? - TopDown: 결론부터 이야기하는 것 (전략적으로 어떻게 갈까 → ex) 블랙리스트 제거하는 방안)
[우리 조] topdown의 형식이 아닌 나열이다. 윗부분만 봤을 때도 이해가 가야한다. 그래프를 보여주기 보다는 말로만 하거나 숫자를 자세히 써주어야한다. (데이터를 유리한 쪽으로 끌고가기, 책잡힐 그래프 쓰지 않기 (우리 것도 숫자로만 제시했으면 책잡히지 않음!)) - 이제부터 ~ 보고를 시작하겠습니다.
- Dataset 간단한 정보 이야기하기 (필드명 이런거X, 자랑하듯이 이야기)
: 기간 이야기하기, 총매출, 총profit 등을 다 이야기해야한다. - 내가 정한 목표 이야기 but 반대를 물어볼 수 있기 때문에 대답을 생각해야함: 로열 고객을 볼 때 → 왜 나쁜 고객은 안봐요? = (계산을 해봤을 때 나쁜 고객을 관리하는 것이 cost가 더 들기 때문입니다)
- 현재 회사가 어떻게 하고 있는지 매출, profit은 매달 암기해야한다
- why를 세 뭉텅이로 나눠서 언급 꼭 하기 (경쟁사, 자사, 시장) 뭐가 없는 경우 뭐를 구축하고 있기 때문에 자사에 대한 이야기를 해보겠습니다. (먼저 선수치기) 다른 팀에서 하고 있다고 거짓말?
[DB가 불안정한 경우]
y =2x + 3 → 2(sum(sales)) + 3
만약 내 식이 너무 복잡하다면 x가 자주 바뀌는 경우도 있다.
x라는 계산식을 따로 만든 후 위 식에 그대로 넣기 → x에 있는 계산식만 바꾸어도 모두 바뀐다
- 여러 개 쓰이고 변동이 있을 것 같다 → 빼기!
[회사의 인증을 받은 DB사용 시]
변동이 없는 경우 모두 합치기 (ex. ATTR로 덮기)
datediff 등 날짜 함수에서 많이 사용한다.
합쳐지지 않은 경우 만든 사람만 트래킹 가능하다.
데이터셋이 작을 수록 쓰기 좋다.
계산식 및 함수
if then

Primary 함수
- Primary 함수는 Primary 함수 내에 다른 함수가 포함된다.
- 한계: 화면에 없으면 볼 수 없다. 엑셀처럼 나열되는 데이터는 괜찮은데 짤라서 보고 싶거나 원하는 결과값을 행으로 보는 것은 불가능하다.
- 분기별 avg, sum을 볼 때 많이 사용
Sales를 기준으로 비교해서 보기
Total()

- 차원으로 나뉘는 것을 상관쓰지 않는다.
- 퍼센티지 잴 때 많이 사용된다.
- 알라바마?
Window()
window_avg / sum()

- 위의 식 경우 그냥 Sum(sales)와 결과가 동일하다.

- 저번달, 이번달, 다음달
- 예시
- 현재달 포함해서 3달 보기: (-2, 0)
- 이번달은 결산안나서 이번달 빼고 3달: (-3, -1)
- if then 기능으로 window_avg가 3개가 아닌 경우 만들지 말라고 지정해줄수 있다.
or 3개일 경우만 값 내게 할수 있다.
Lookup()

- MOM구할 때 많이 쓰인다.
- 차원에 따라 -1이 가지는 의미가 달라진다. (차원 조종 가능)
- 위에 값이 있어야 확인할 수 있다.
Running()
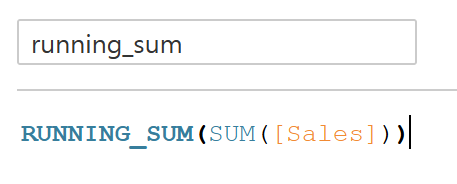
- 누계로 계산된 필드를 만들 수 있다. (응용 가능)
- 퀵테이블 계산에 의존하지 말기!
- 숨기기의 안좋은점: 자동화로 인해 db도는 순간 다 풀린다!
- 필터걸거나 제거하면 그 데이터 없이 작업이 진행된다.
Previous_value()

- 이전 행이 없으면 그 값을 반환한다.
- previous_value: 0, 1

Rank

- SQL에서 rank 뽑지 않기: 차원이 달라지면 엉킨다.
- 행으로 가져오고 싶으면 불연속형으로 변경
- rank는 차원으로 놓는 것이 가장 깔끔하다.
연도별, 분기별, 일별
if then 이용하여 window_avg가 -1,1인 경우 3개가 딱 있을 경우에만 값이 나오도록 식만들기
orderdate 문자열로 바꾼 뒤 사용해보기
연속형 불연속형의 차이
- 불연속형
- 정해진 범위가 있다
- 연속형
- 측정값: 범위가 무한하다
- 차원 우클릭 > 측정값으로 변환 (count)
[오늘의 숙제]
설명안해도된다.
- 오늘 배운 함수 응용하여 그래프 3개 만들기
- 제목칸에 기능적기
- 매개변수 사용하기
: 단일만 선택 M-1(11), M-2(10) (오늘이 2022/12) → 시도해보기 (날짜 매개변수)
어려우면 아무 매개변수라도!
- 문자열 목록 이용해서 만들기

잘 이해가 안되는 부분
- sum - lookup 그래프에서 불연속형으로 지정하니 각 1월이 끊겨서 나오는 것 해결방안이 있는지?
해결방법: sum - lookup 우클릭 > 다음을 사용하여 계산 > order date
오늘의 과제!


디지털 리터리시 목차
[섹션 1] 메가 트렌드 & 사례
[섹션 2] 의사결정과 데이터
[섹션 3] 데이터 리터리시
[섹션 4] 데이터란 무엇인가
[섹션 5] 데이터 기획 리터러시
[섹션 6] 데이터 수집 리터러시
[01] 메가 트렌드 & 사례
월마트 사례
- 현재 월마트의 경쟁자: 테크 프론티어 아마존 (연도별 순수익이 증가하고 있음)
- 2015년 기준 아마존이 월마트 시가 총액을 추월했다.
- 월마트의 디지털 전환
- 월마트 "Market Place" 론칭
- Walmart Labs
- 폴라리스
→ 월마트의 폭발적인 성장
Digital Transformation
- Super Jobs
- Zero to Hero
- 디지털 역량 확보의 필요성
- 데이터 마인드 Building (데이터 리터러시)
[02] 의사결정과 데이터
직관적 의사결정과 데이터 기반 의사결정
- 경영 = 의사결정 (직관 + 데이터)
- 직관적 의사결정: 경험, 직관의 중요성
- 데이터 기반 의사결정: 확률
Case - 코노코필립스
- 하인리히의 법칙 (징후)
- 코노코필립스의 시추선 고장 방지
데이터 기반 의사결정 모형
- 대다수 데이터 기반 문제 해결자 역량이 중요함
: 비즈니스 애널리스트, 데이터 전략가, 데이터 과학자 - PPDAC 모형: 문제 정의 → 계획 → 데이터 → 분석 → 결론
데이터 기반 전략 수립 사례
소주 회사 신상품 출시 전략
- KESS 다운로드
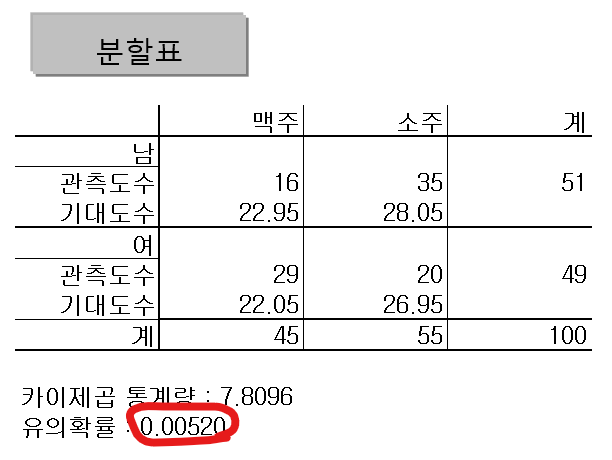
➡️ 성별에 따른 주종 선호도는 유의미한 차이가 있다.
: 남자는 소주(도수↑, 알콜향), 여자는 맥주(도수↓, 보리향)를 더 좋아한다.
- 가설: 여자는 도수는 낮고, 향이 좋은 술을 좋아한다.
[섹션 3] 데이터 리터리시
- 데이터 리터리시 필요 역량: 기획 > 수집 > 처리 > 분석 > 시각
[섹션 4] 데이터란 무엇인가
데이터 유형
- 비정형 데이터 ex. 썸트렌드
- 정형 데이터 ex. 테이블
- 데이터는 문자 또는 숫자이다.
- 데이터는 범주형(문자 - 명목, 서열) 또는 연속형(숫자 - 등간, 비율)으로 분류한다.
DIKW 피라미드
- Data > Information > Knowledge > Wisdom
[섹션 5] 데이터 기획 리터러시
- 데이터 분석 종합 역량
- 비즈니스 도메인 지식&경험(KW에 중요)
- 분석 모델
- 통계 지식
- 분석 도구(Tool) 매뉴얼 활용 역량
- 데이터 분석 실무 프로세스: 분석 목적(BQ) 정하기 > 데이터 수집 및 정제 > 데이터 탐색(EDA) > 분석 결과 시각화 및 공유 > 의미 도출
- 데이터 분석 모델: 잔차오차가 적은 모델이 좋은 모델이다.
- Case: Kroger → 로열 고객 집중 전략
- ABC 분석 모델: 전체 매출액에서 고객군이 차지하는 비중을 기준으로 고객 등급을 분류하는 방법
- RFM 분석 모델: 각 고객의 구매 금액, 방문 횟수, 최신성을 종합적으로 고려해 고객의 등급을 분류하는 방법
- 모형화 전략
- 좋은 데이터 분석 모델 만들기: 분해 > 패턴인식 > 추상화 > 알고리즘화
- 좋은 데이터 분석 모델 만들기: 분해 > 패턴인식 > 추상화 > 알고리즘화
- 분석 목표 KPI 도출 프레임워크: BSC(Balanced Score Card)
- Financial < Customer < Internal Process < Learning & Growth
[섹션 6] 데이터 수집 리터러시
- 데이터는 직접 수집하거나 외부에서 취합한다.
- 1차 자료 수집: 서베이
- 2차 자료 수집: crawling(크롤링)
→ URL과 엑셀 사용 - 로그 데이터의 기계적 수집
- 추적코드를 헤더에 넣어 이용자를 관찰한다.
- 데이터 태깅과 라벨링
- 태그
- 라벨(라벨링, 라벨러)
✍️ 마무리하며
오늘은 숙제가 많지 않아서 숙제를 마무리하고 유데미 강의를 수강했다. 데이터 리터리시에 대한 강의를 들었는데 오랜만에 한국어 강의이기도 하고 내용도 흥미로워서 순식간에 6파트나 들었다!! 😮 내일도 화이팅!
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌 본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 32일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.22 |
|---|---|
| [👩💻TIL 31일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.21 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습 일지 (0) | 2023.03.19 |
| [👩💻TIL 29일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.17 |
| [👩💻TIL 28일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.03.16 |



