
홍동이의 성장일기
[👩💻TIL 46일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

태블로에 PostgreSQL 연결하는 방법

1. 위 파일을 압축해제 하지 않고 C:\Program Files\Tableau\Drivers에 담는다.
2. dbeaver에서 edit connection

3. 입력창에 나오는 정보들을 참고하여 태블로 연결창에 입력


4. 연결 완료!


sql을 태블로에 연결해서 다양한 시각화를 해봅시다~
[더 보면 좋았을 것]
orders date 기간 (언제 쉬는날인지 등)
제품은 뭐가 있는지
select 구문 키워드
- distinct: 중복 추출 제거
- *
- alias
- 테이블명
- where
- 조건(condition)
- order by: asc(생략), desc
-- 전체 데이터 추출 --
select *
from customers c ;
-- country 컬럼만 추출 --
select country
from customers c ;
-- country 고유값 추출 --
select distinct(country)
from customers c ;
-- country 고유값 개수 --
select count(distinct(country))
from customers c;
-- country 고유값 개수에 별칭 주기 --
select count(distinct(country)) as country_cnt
from customers c;select distinct country, city
from customers c
order by country asc, city desc;
select company_name
from customers c
order by 1
limit 3;
-- 할인 적용된 컬럼
select *, unit_price * quantity * (1-discount) as tot
from order_details od ;
select concat(address,' ', city, ' ',region, postal_code, ' ', country) as full_address
from customers c ;
select address||city||region as full_address
from customers c ;
null이 있으면 연산 불가
➡️ null 연산의 결과는 null
select coalesce (address,'') ||' '|| coalesce (city,'') ||' '|| coalesce (region,'') ||
coalesce (region,'') || coalesce (postal_code ,'') ||' '|| coalesce (country,'') as full_address
from customers c ;
※ coalesce 함수: 인자로 주어진 컬럼들 중 null이 아닌 첫번째 값을 반환하는 함수 (ansi 표준)
➡️ null이면 다른 값으로 변환하는데 사용하기도 한다.
- mysql: if null
- oracle: NVL
※ nullif 함수: 단일 행 함수 > NULL 관련 함수 > 특정 값을 NULL 처리하기
➡️ NULLIF(표현식1, 표현식2): 표현식1 = 표현식2 이면 NULL
select category_name , nullif (category_name, 'Beverages')
from categories c ;
날짜/시간형 데이터 다루기
📍데이터타입
- timestamp: 날짜와 시간
- date: 날짜
- time: 시간
- interval: 날짜 차이 ex. 1 days, 1 mon, 100 years
📍현재 날짜, 시간 가져오기
select now();
➡️ 표준시간보다 9시간 빠르다는 뜻
select current_timestamp ;
select localtimestamp ;
select current_date ;
select current_time ;
select localtime ;




📍자료형 변환
- cast(변환대상 as 자료형)
- 변환대상 :: 자료형
select cast(now() as date);
select now()::date;
select cast(now() as time);
select now()::time;
📍 단일 행 함수 > 날짜 함수
- now()
- extract('part' from 날짜/시간타입)
select extract ('year' from now());※ 'year' 자리에 month, day, quarter, hour, minute, seconds, dow가 들어갈 수 있다.

- date_part('part', 날짜/시간타입)
select date_part('year', now());

➡️ integer로 결과 반환
- date_trunc('part', 날짜/시간타입): 밑에를 다 비워버림
select date_trunc('year', now());
➡️ timestamp로 결과 반환
- to_char(날짜/시간타입, 'part')
select to_char(now(), 'YYYY');※ YYYY자리에 MM, DD, HH, HH24, MI, SS, YYYY-MM, YYYYMM, MMDD, HH24:MM:SS, mon, MON, day, DAY, quarter, QUARTER가 들어갈 수 있다.

➡️문자형으로 결과 반환
-- 2023년 4월 9일은 무슨 요일?
select extract('dow' from '2023-04-09'::date);
select date_part('dow', '2023-04-09'::date);
select to_char('2023-04-09'::date, 'day');
-- orders 테이블에서 order_date의 '연도-월' 출력하기
select order_date, to_char(order_date, 'YYYY-MM') as year_month
from orders;
-- orders 테이블에서 order_date의 '연도-분기' 출력하기
select order_date, to_char(order_date, 'YYYY년-q분기') as year_quarter
from orders;
단일 행 함수(스칼라 함수): 문자, 숫자, 날짜, 변환, NULL 관련 함수
다중 행 함수(그룹 함수)
- 다중 행을 인자로 받아들여 한 개의 값으로 결과를 반환하는 함수
- 집계함수(전체 레코드에 대한 집계, 소그룹에 대한 집계)
- COUNT(*)
- COUNT(DISTINCT 표현식)
- SUM, AVG,MAX, MIN, STDDEV, VARIANCE
📍 GROUP BY, HAVING 절
- SELECT에 나오는 컬럼이 GROUP BY에 사용된 컬럼이어야 한다.
- HAVING은 GROUP을 대상으로 한 조건이다.
작성 순서: SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
-- 전체 고객 수
select count(*) as customer_cnt
from customers c ;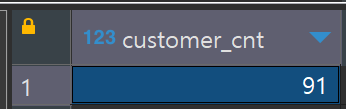
➡️ count(*) 집계 함수 외에 다른 컬럼을 같이 쓸 수 없다. 반드시 group by를 해주어야 한다.
-- 국가별 고객 수
select country, count(customer_id) as cnt
from customers c
group by country
order by 1;
-- USA 고객 수 (1)
select country, count(customer_id) as cnt
from customers c
where country = 'USA'
group by country;
-- USA 고객 수 (2)
select country, count(customer_id) as cnt
from customers c
group by country
having country = 'USA';
-- 고객 수가 10 이상인 국가
select country, count(customer_id) as cnt
from customers c
group by country
having count(customer_id) >= 10;
➡️ where절 사용 불가 (집계된 것에서 조건을 주어야 하기 때문에)
- HAVING절에 cnt(ALIAS) 사용 불가
쿼리의 실행 순서: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT 등
따라서 ALIAS 사용 불가
💲구매지표 추출
- 매출액(일자별, 월별, 분기별)
- 구매자수, 구매건수(일자별, 월별, 분기별)
- 인당 매출액(월별, 분기별)
- 건당 구매금(월별, 분기별)
-- 총 매출액
select sum(unit_price * quantity * (1-discount)) as 총매출액
from order_details od ;
-- 총 주문건수
select count(*) as 총주문건수
from orders o ;
-- 총 상세 주문건수
select count(*) as 총상세주문건수
from order_details od ;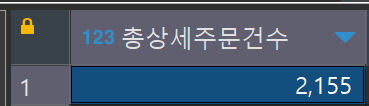
-- 총 주문 수량 (quantity sum)
select sum(quantity) as 총주문수량
from order_details od ;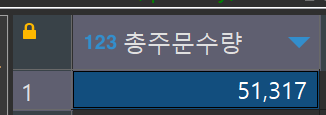
일별 구매지표 추출
- 일별 매출액
- 필요한 데이터는 무엇인가?
- 필요한 데이터는 어떤 테이블에 존재하는가? orders(order_date), order_details(unit_price, quantity, discount)
- 테이블을 어떻게 결합할 것인가? 조인
-- 일별 매출액
-- 1. 필요한 데이터 불러오기
select o.order_date, od.unit_price, od.quantity, (1-od.discount)
from orders o, order_details od
where o.order_id = od.order_id ;
-- 2. 주문별 매출액 구하기
select o.order_date, od.unit_price * od.quantity * (1-od.discount) as 매출액
from orders o, order_details od
where o.order_id = od.order_id ;
-- 3. 일별 매출액 구하기
select o.order_date, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 4. 검증
select sum(매출액) from(
select o.order_date, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1
) a ;
➡️ 서브쿼리 사용하여 계산 (이름 꼭 만들어주기!)
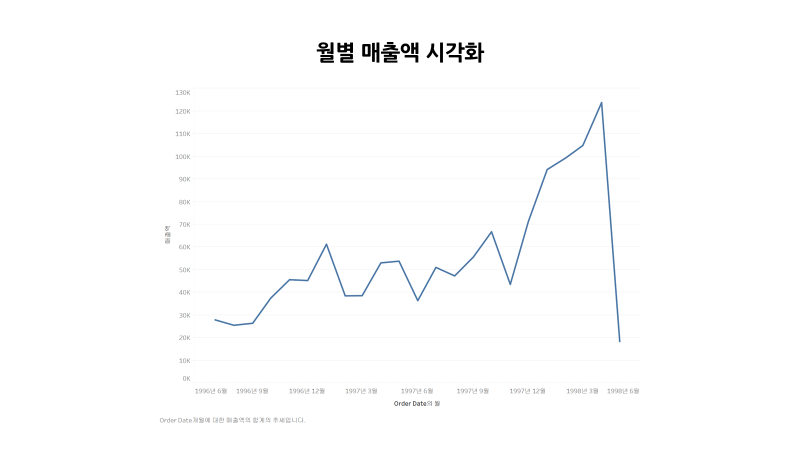
5. 태블로 연결하여 시각화 해주기

➡️ 매출이 오르고 있는 추세를 확인할 수 있다. (특히 후반부에)
-- 1997년 일별 매출액
select o.order_date, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
having to_char(order_date, 'YYYY')='1997';
- 일별 주문 건수
- 필요한 데이터는 무엇인가?
- 필요한 데이터는 어떤 테이블에 존재하는가? orders (order_date, order_id)
- 테이블을 어떻게 결합할 것인가?
-- 일별 주문 건수
select order_date, count(order_id)
from orders o
group by order_date
order by 1;
-- 검증
select sum(주문건수)
from (
select order_date, count(order_id) as 주문건수
from orders o
group by order_date
order by 1
) a;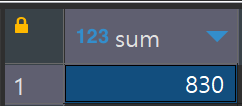
시각화

➡️ 주문건수가 늘어나고 있다는 것을 확인할 수 있다.
- 일별 구매자수
- 필요 테이블: orders
-- 일별 구매자수
select order_date, count(distinct customer_id) as 구매자수
from orders o
group by order_date
order by 1
-- 검증
select sum(구매자수)
from (
select order_date, count(distinct customer_id) as 구매자수
from orders o
group by order_date
order by 1
) a;
➡️ 여러 번 구매한 고객의 경우 customer_id가 여러번으로 나타나므로 distinct를 해주어야 한다.
시각화

하나의 쿼리로 만들기
-- 일별 매출액, 구매건수, 구매자 수 하나의 쿼리로 만들기
select o.order_date
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 검증
select sum(매출액),sum(주문건수),sum(구매자수)
from (
select o.order_date
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1
) a;
➡️ orders랑 order_details가 order_id를 기준으로 1대 다 관계를 가지고 있기 때문에 조인을 할 경우 order_id에도 distinct를 해주어야 한다.
📍과제

※ 월별(월로만 그룹핑X 연도가 다르기 때문에), 분기별
-- 월별 매출액, 구매건수, 구매자 수 하나의 쿼리로 만들기
select to_char(o.order_date, 'YYYY-MM')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 검증
select sum(매출액),sum(주문건수),sum(구매자수)
from (
select to_char(o.order_date, 'YYYY-MM')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1
) a;
-- 월별 인당 평균 매출액
select to_char(o.order_date, 'YYYY-MM')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.customer_id) as 구매자수
, sum(od.unit_price * od.quantity * (1-od.discount)) / count(distinct o.customer_id) as 인당평균매출액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 월별 건당 평균 구매 금액
select to_char(o.order_date, 'YYYY-MM')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, sum(od.unit_price * od.quantity * (1-od.discount)) / count(distinct o.order_id) as 건당평균구매금액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;


-- 분기별 매출액, 구매건수, 구매자 수 하나의 쿼리로 만들기
select to_char(o.order_date, 'YYYY-Q')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 검증
select sum(매출액),sum(주문건수),sum(구매자수)
from (
select to_char(o.order_date, 'YYYY-Q')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, count(distinct o.customer_id) as 구매자수
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1
) a;
-- 분기별 인당 평균 매출액
select to_char(o.order_date, 'YYYY-Q')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.customer_id) as 구매자수
, sum(od.unit_price * od.quantity * (1-od.discount)) / count(distinct o.customer_id) as 인당평균매출액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;
-- 분기별 건당 평균 구매 금액
select to_char(o.order_date, 'YYYY-Q')
, sum(od.unit_price * od.quantity * (1-od.discount)) as 매출액
, count(distinct o.order_id) as 주문건수
, sum(od.unit_price * od.quantity * (1-od.discount)) / count(distinct o.order_id) as 건당평균구매금액
from orders o, order_details od
where o.order_id = od.order_id
group by 1
order by 1;


상관관계가 태블로에서 잘 안만들어져서 파이썬에서 보기 위해 코드를 작성하는데 릴레이션 오류가 발생했다.
UndefinedTable: 오류: "orders" 이름의 릴레이션(relation)이 없습니다
LINE 6: from orders o, order_details od
[PostgreSQL] Schema 접근 에러
PostgreSQL Schema 접근 에러 스키마, 테이블도 만든 상태이나 테이블 조회시 아래와 같은 오류가 나는 경우 "ERROR: 오류: "TABLE_NAME" 이름의 릴레이션(relation)이 없습니다." 해결방법 1. 스키마명.테이블
javaoop.tistory.com
구글링을 해보니 테이블명 앞에 스키마명을 붙여줘야 했다.
테이블명 앞에 northwind를 붙여주니 오류 해결!
상관관계를 표현해준 코드는 다음과 같다.
import plotly
import sqlalchemy
# !pip install psycopg2
import pandas as pd
import psycopg2
from sqlalchemy import create_engine
conn_string = 'postgresql://postgres:비밀번호@localhost:포트번호/postgres'
postgres_engine = create_engine(conn_string)
query = """
쿼리
"""
df = pd.read_sql_query(sql=query, con=postgres_engine)
corr = df.corr()
print(corr) # 상관관계 확인
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings # 경고창 없애주는 코드
warnings.filterwarnings(action='ignore')
# sns에서 한글 깨져서 넣어준 코드
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/NGULIM.TTF"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
# 상관관계 시각화
mask = np.triu(np.ones_like(corr, dtype=np.bool))
mask[np.triu_indices_from(mask)] = True
plt.figure(figsize=(10,8))
sns.heatmap(corr, cmap = 'Greens', annot=True, fmt='.2f', mask=mask)
plt.show()시각화까지 한 결과물은 다음과 같다.










SQL 재미있다!! 내가 원하는 대로 테이블을 마구마구 뽑아내는 그날까지 화이팅!! 💪
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌 본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 48일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.04.13 |
|---|---|
| [👩💻TIL 47일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.04.12 |
| [👩💻TIL 45일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.04.10 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 9주차 학습 일지 (0) | 2023.04.07 |
| [👩💻TIL 44일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.04.07 |



