
홍동이의 성장일기
[👩💻TIL 8일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
[상가(상권)정보 분석, 시각화]
[SQL을 통한 데이터활용과 분석]
[118차시]실습: MySQL 설치, 개발환경 사용, Workbench 사용
[119차시]Schema,Table 구성 이해. SQL 언어 DDL과 DML 소개
[121차시]DDL 이용 스키마 생성, DML 구문 사용하기
[124차시]실습: INSERT, DELETE, UPDATE사용하기
[125차시]Where 조건 지정과 논리, 비교연산자, 패턴 매칭 이해
[127차시]LIMIT, ORDER BY, CASE 구문 통한 조건 제어
[115차시]데이터수집
[116차시]데이터 확인 및 전처리
- 라이브러리 임포트
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family']='Malgun Gothic'
plt.rcParams['axes.unicode_minus']=False
데이터 수집¶
데이터프레임 생성¶
- 17개 파일의 데이터를 각각 데이터프레임으로 만든 후 합친다.
17개의 파일을 각각 데이터프레임으로 만들기¶
- column에 NaN값이나 여러 type의 데이터가 섞여 있으면 DtypeWarning 발생
dtype option으로 타입을 명시해주거나 low_memory = False로 지정해 주면 경고 메시지가 출력되지 않는다.
df1 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_강원_202109.csv')
df2 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_경기_202109.csv')
df3 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_경남_202109.csv')
df4 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_경북_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\4086427500.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df4 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_경북_202109.csv')
df5 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_광주_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\4146615270.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df5 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_광주_202109.csv')
df6 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_대구_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\4272118517.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df6 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_대구_202109.csv')
df7 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_대전_202109.csv')
df8 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_부산_202109.csv')
df9 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_서울_202109.csv')
df10 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_세종_202109.csv')
df11 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_울산_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\4118380753.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df11 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_울산_202109.csv')
df12 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_인천_202109.csv')
df13 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_전남_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\3492479529.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df13 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_전남_202109.csv')
df14 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_전북_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\1283157121.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df14 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_전북_202109.csv')
df15 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_제주_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\2855960813.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df15 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_제주_202109.csv')
df16 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_충남_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\3915843117.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df16 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_충남_202109.csv')
df17 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_충북_202109.csv')
C:\Users\neulu\AppData\Local\Temp\ipykernel_21028\2074920294.py:1: DtypeWarning: Columns (35) have mixed types. Specify dtype option on import or set low_memory=False.
df17 = pd.read_csv('data/소상공인시장진흥공단_상가(상권)정보_충북_202109.csv')
데이터프레임 연결하기¶
- pd.concat(데이터프레임리스트) : 행 방향으로 연결
- pd.concat(데이터프레임리스트, axis=1) : 열 방향으로 연결
- 인덱스 재지정 : ignore_index = True
# 데이터프레임 합치기 : [df1,df2,df3,df4,df5,df6,df7,df8,df9,df10,df11,df12,df13,df14,df15,df16,df17]
df = pd.concat([df1,df2,df3,df4,df5,df6,df7,df8,df9,df10,df11,df12,df13,df14,df15,df16,df17], ignore_index=True)
💡동일한 인덱스가 중복되어서 처리됨
len(df.columns)
39# 컬럼갯수 최대 지정
pd.options.display.max_columns=39
df.head(1)
| 상가업소번호 | 상호명 | 지점명 | 상권업종대분류코드 | 상권업종대분류명 | 상권업종중분류코드 | 상권업종중분류명 | 상권업종소분류코드 | 상권업종소분류명 | 표준산업분류코드 | 표준산업분류명 | 시도코드 | 시도명 | 시군구코드 | 시군구명 | 행정동코드 | 행정동명 | 법정동코드 | 법정동명 | 지번코드 | 대지구분코드 | 대지구분명 | 지번본번지 | 지번부번지 | 지번주소 | 도로명코드 | 도로명 | 건물본번지 | 건물부번지 | 건물관리번호 | 건물명 | 도로명주소 | 구우편번호 | 신우편번호 | 동정보 | 층정보 | 호정보 | 경도 | 위도 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 25033300 | 동그라미중고타이어 | NaN | D | 소매 | D23 | 자동차/자동차용품 | D23A04 | 타이어판매 | G45211 | 자동차 타이어 및 튜브 판매업 | 42 | 강원도 | 42150 | 강릉시 | 4215057100 | 포남1동 | 4.215011e+09 | 포남동 | 4215011100110960006 | 1 | 대지 | 1096 | 6.0 | 강원도 강릉시 포남동 1096-6 | 4.215032e+11 | 강원도 강릉시 가작로 | 270 | NaN | 4215011100110960006010791 | NaN | 강원도 강릉시 가작로 270 | 210110.0 | 25488.0 | 1 | NaN | NaN | 128.904472 | 37.770252 |
데이터 확인 및 전처리¶
데이터 크기¶
df.shape
(2245938, 39)데이터프레임 정보¶
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2245938 entries, 0 to 2245937
Data columns (total 39 columns):
# Column Dtype
--- ------ -----
0 상가업소번호 int64
1 상호명 object
2 지점명 object
3 상권업종대분류코드 object
4 상권업종대분류명 object
5 상권업종중분류코드 object
6 상권업종중분류명 object
7 상권업종소분류코드 object
8 상권업종소분류명 object
9 표준산업분류코드 object
10 표준산업분류명 object
11 시도코드 int64
12 시도명 object
13 시군구코드 int64
14 시군구명 object
15 행정동코드 int64
16 행정동명 object
17 법정동코드 float64
18 법정동명 object
19 지번코드 int64
20 대지구분코드 int64
21 대지구분명 object
22 지번본번지 int64
23 지번부번지 float64
24 지번주소 object
25 도로명코드 float64
26 도로명 object
27 건물본번지 int64
28 건물부번지 float64
29 건물관리번호 object
30 건물명 object
31 도로명주소 object
32 구우편번호 float64
33 신우편번호 float64
34 동정보 object
35 층정보 object
36 호정보 object
37 경도 float64
38 위도 float64
dtypes: float64(8), int64(8), object(23)
memory usage: 668.3+ MB
서브셋 만들기¶
# 컬럼명 가져오기
df.columns
Index(['상가업소번호', '상호명', '지점명', '상권업종대분류코드', '상권업종대분류명', '상권업종중분류코드',
'상권업종중분류명', '상권업종소분류코드', '상권업종소분류명', '표준산업분류코드', '표준산업분류명', '시도코드',
'시도명', '시군구코드', '시군구명', '행정동코드', '행정동명', '법정동코드', '법정동명', '지번코드',
'대지구분코드', '대지구분명', '지번본번지', '지번부번지', '지번주소', '도로명코드', '도로명', '건물본번지',
'건물부번지', '건물관리번호', '건물명', '도로명주소', '구우편번호', '신우편번호', '동정보', '층정보',
'호정보', '경도', '위도'],
dtype='object')필요한 컬럼만 추출하여 서브셋 만들기¶
- 서브셋을 만들 때는 copy()기능을 사용하는 것을 권장
df_store = df[['상호명','상권업종대분류명','상권업종중분류명','상권업종소분류명','시도명','시군구명','행정동명','법정동명','경도','위도']].copy()
df_store.head()
| 상호명 | 상권업종대분류명 | 상권업종중분류명 | 상권업종소분류명 | 시도명 | 시군구명 | 행정동명 | 법정동명 | 경도 | 위도 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 동그라미중고타이어 | 소매 | 자동차/자동차용품 | 타이어판매 | 강원도 | 강릉시 | 포남1동 | 포남동 | 128.904472 | 37.770252 |
| 1 | 세인트존스호텔Ohcrab | 숙박 | 호텔/콘도 | 호텔/콘도 | 강원도 | 강릉시 | 초당동 | 강문동 | 128.920908 | 37.791299 |
| 2 | 평창라마다호텔 | 숙박 | 호텔/콘도 | 호텔/콘도 | 강원도 | 평창군 | 대관령면 | 대관령면 | 128.717971 | 37.660051 |
| 3 | 호텔탑스텐스카이라운지 | 숙박 | 호텔/콘도 | 호텔/콘도 | 강원도 | 강릉시 | 옥계면 | 옥계면 | 129.052902 | 37.654680 |
| 4 | 족발야시장 | 음식 | 한식 | 족발/보쌈전문 | 강원도 | 강릉시 | 교1동 | 교동 | 128.878636 | 37.765339 |
서브셋 데이터 확인¶
# 데이터 크기
df_store.shape
(2245938, 10)# 데이터 정보(메모리 용량이 줄어듦)
df_store.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2245938 entries, 0 to 2245937
Data columns (total 10 columns):
# Column Dtype
--- ------ -----
0 상호명 object
1 상권업종대분류명 object
2 상권업종중분류명 object
3 상권업종소분류명 object
4 시도명 object
5 시군구명 object
6 행정동명 object
7 법정동명 object
8 경도 float64
9 위도 float64
dtypes: float64(2), object(8)
memory usage: 171.4+ MB
결측치분석/처리¶
df_store.isnull().sum()
상호명 2
상권업종대분류명 0
상권업종중분류명 0
상권업종소분류명 0
시도명 0
시군구명 0
행정동명 11839
법정동명 1453
경도 0
위도 0
dtype: int64💡별도의 결측치 처리X
상권업종분류¶
print(df_store['상권업종대분류명'].unique())
print(df_store['상권업종대분류명'].nunique())
['소매' '숙박' '음식' '학문/교육' '생활서비스' '부동산' '관광/여가/오락' '스포츠']
8
df_store['상권업종중분류명'].nunique()
89df_store['상권업종소분류명'].nunique()
716상권업종분류표¶
df_store_class = df_store[['상권업종대분류명','상권업종중분류명','상권업종소분류명']].drop_duplicates().sort_values(['상권업종대분류명','상권업종중분류명','상권업종소분류명'])
# 상권업종 분류표 모두보기(최대 행 수 지정)
pd.options.display.max_rows=20
df_store_class
| 상권업종대분류명 | 상권업종중분류명 | 상권업종소분류명 | |
|---|---|---|---|
| 8094 | 관광/여가/오락 | PC/오락/당구/볼링등 | 기원 |
| 2885 | 관광/여가/오락 | PC/오락/당구/볼링등 | 당구장 |
| 4683 | 관광/여가/오락 | PC/오락/당구/볼링등 | 볼링장 |
| 44597 | 관광/여가/오락 | PC/오락/당구/볼링등 | 비디오감상실 |
| 53746 | 관광/여가/오락 | PC/오락/당구/볼링등 | 오락용사격장 |
| ... | ... | ... | ... |
| 140419 | 학문/교육 | 학원기타 | 학원-모델 |
| 101249 | 학문/교육 | 학원기타 | 학원-실내운전 |
| 11474 | 학문/교육 | 학원기타 | 학원-심리변론 |
| 162249 | 학문/교육 | 학원기타 | 학원-역학 |
| 115129 | 학문/교육 | 학원기타 | 학원-침술 |
716 rows × 3 columns
[117차시]RDBMS 소개/설치와 개발환경 소개
데이터베이스: 목적에 맞도록 관련된 데이터를 모아두기 위한 방법
- 데이터의 집합
- 여러 명의 사용자, 응용프로그램이 공유
- 동시 접근이 가능해야 함
- '데이터의 저장공간' 자체를 의미하기도 함
DBMS
- 데이터베이스를 관리/운영하는 역할
- 동시 사용 가능한 데이터 저장공간을 위한 시스템과 응용 프로그램
데이터베이스의 기능적 특징
- 데이터 정의(Definition)
- 데이터 조작(Manipulation)
- 데이터 추출(Retrieval)
- 데이터 제어(Control)
- 트렌젝션의 실현성 보장
- DBMS가 자체적으로 제공하는 백업/복원 가능
- 데이터 손실 시 복원/복구
데이터베이스의 종류
- 관계형 데이터베이스(Relational Database = RDB)
- 데이터를 키와 값의 관계로 구성한 테이블로 구성해 관계대수로 조작
- 사용자는 SQL이라는 표준 질의어를 통해 데이터를 조작 또는 조회할 수 있음
- 현재 사용되는 DBMS 중 가장 많은 부분 차지
- 일련의 정형화된 테이블로 구성된 데이터 항목들의 집합이며 각 테이블은 데이터의 성격에 따라 여러 개의 컬럼(키)이 포함됨
- 데이터의 무결성/독립성
- 보안
- 데이터 중복의 최소화
- SQL 언어(Structured Query Language)
- 객체지향 데이터베이스(Object Oriented Database = OODB)
- 정보를 객체의 형태로 표현하는 데이터베이스
- 객체 모델이 적용되어 데이터 모델을 그대로 응용프로그램에 적용
- 객체관계형 데이터베이스(Object Relation Database = ORDB)
- 관계형 데이터베이스 + 객체지향 데이터베이스
- 관계형 데이터베이스 + 객체지향 데이터베이스
- NOSQL
- 대용량 데이터, 비정형 데이터의 웹 서비스와 SNS, 클라우드 컴퓨팅의 확대 보급과 대중화로 최근 주목받고 있는 데이터베이스 기술
- 대용량 데이터, 비정형 데이터의 웹 서비스와 SNS, 클라우드 컴퓨팅의 확대 보급과 대중화로 최근 주목받고 있는 데이터베이스 기술
- MySQL
- Open source DB로 탄생
- LAMP/SAMP stack 기반으로 사용층 확보
- 상용 DB대비 DB관리 TCO에 유리
- 최상의 신뢰성, 보안성 제공
- Stored Procedure, Trigger, View 등 RDBMS로서 기본 기능에 충실
- Pluggable Storage Engine 제공
- 다양한 Third 파트 엔진 지원
- 다양한 관리용 GUI 툴 제공: Administration, Migration, Backup, Workbench, Query Browswer 등
- 중앙 집중 관리: 보안, 스키마 관리, Replication, 성능 모니터링 등
- 다양한 Platform 지원: 가격대비 최대 성능 효과의 TCO 절감 DBMS
- MySQL Community Edition

- MySQL8 특징
- SQL, JSON 및 GIS와 같은 분야의 요청 새로운 기능을 제공
- Emojis를 저장할 수 있는 UTF8MB4가 default character set
- NoSQL Document Store: 기존 SQL 관계형 + NoSQL 문서 데이터베이스 가능
- SQL WINDOW 함수, Common Table, NOWAIT 및 SKIP LOCKED, 내림차순 인덱스, Grouping, 정규식, Character Sets, Cost Model 및 히스토그램
- JSON Extended 구문, 새로운 기능, 향상된 정렬 및 부분 업데이트
JSON TABLE 함수를 사용하면 JSON 데이터용 SQL machinery 사용 가능 - GIS Geography 지원: Spatial Reference Systems(SRS)뿐만 아니라 SRS aware spatial 데이터 유형, spatial 인덱스 및 spatial 함수 등이 있음
- Reliability DDL문은 원자성 및 충돌 안전성이 있으며 meta-data는 트랜잭션 데이터 사전에 싱글 저장됨
- Observability Performance Schema, Information Schema, Invisible Indexes, Error Logging
- Manageability Persistent Configuration 변수, Undo tablespace 관리, Restart 명령어 및 새로운 DDL
- High Availability InnoDB Cluster는 데이터베이스에 통합 된 네이티브 HA 솔루션을 제공함
- Security OpenSSL 개선, 새로운 기본 인증, SQL Roles, breaking up the super privilege, 암호 강화, 권한 부여
- Performance는 MySQL 5.7보다 최대 2배 빠름
[118차시]실습: MySQL 설치, 개발환경 사용, Workbench 사용
MYSQL Commyunity Edition 설치
MySQL :: MySQL Community Edition
MySQL Community Edition MySQL Community Edition is the freely downloadable version of the world's most popular open source database. It is available under the GPL license and is supported by a huge and active community of open source developers. The MySQL
www.mysql.com
다운로드 > MYSQL 커뮤니티 서버 > 위에 있는 작은 용량 다운로드 (로그인없이 다운로드 가능)
다운로드 된 파일 설치: Execute로 파일 설치하기
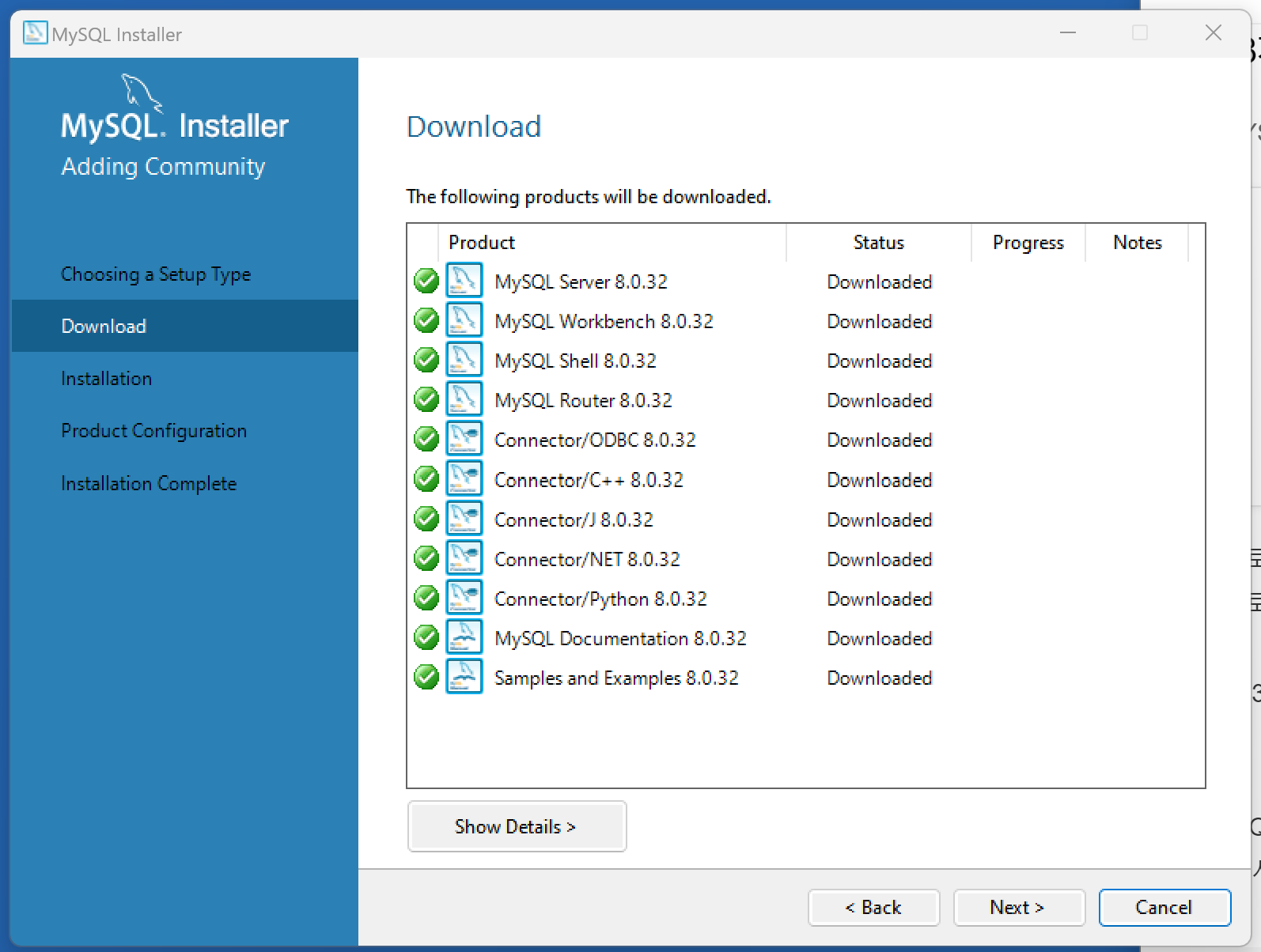

port: 3306, Root 사용자 패스워드 기억해두기
작업관리자 > 서비스 > MySQL8에서 다시 시작하거나 중지할 수 있음
[119차시]Schema,Table 구성 이해. SQL 언어 DDL과 DML 소개
Schema

- 물리적 공간: DBMS에 저장되는 공간
- 논리적 공간: 저장 공간의 영역
- Schema 내부에 Table이 존재한다
- Table
- 데이터베이스는 테이블 기반으로 구성된다
- 테이블은 하나이상의 열로 구성
- Table
관계형 DBMS에서 Table의 개념
- RDBMS의 가장 기본적이고 중요한 구성
- 관계대수에 의해 데이터를 효율적으로 저장하기 위한 구조
- Entity Relation에 의해 불필요한 공간의 낭비 줄이고 데이터의 저장 효율성 보장
- 테이블의 관계(Relation)
- 키본키(Primary Key)와 외래키(Foreign Key)를 사용해 관계 맺어줌
→ 두 테이블을 부모와 자식의 관계로 묶어줌
→ SQL의 조인(JOIN) 기능 이용
- 키본키(Primary Key)와 외래키(Foreign Key)를 사용해 관계 맺어줌
ERD(Entity Relation Diagram)로 분석 및 모델링

- Schema 단위에 논리 모델의 결과물 Table 사용
| 테이블 | DBMS의 기본 저장구조. 한 개 이상의 column 과 0개 이상의 row로 구성 |
| 열(Column) | 특정 데이터 타입 및 크기를 가진 구조 |
| 행(Row) | Column들의 값의 조합으로 레코드라고 불리며 제약사항이 적용됨 |
| Field | Row와 Column의 교차점으로 Field는 데이터를 포함할 수 있고, 없을 때는 NULL 값을 가지고 있다고 함 |
SQL 언어
- Query(질의): 관계형 데이터베이스를 사용할 때 RDBMS에게 보내는 요청

- SQL 특징
- 독립성: DBMS 제작 회사와 독립적
- 제작 회사는 표준 SQL에 맞춰서 DBMS 개발
- 표준 SQL은 대부분의 DBMS 제품에서 공통 호환 - 이식성
- 다른 시스템으로 이식성이 좋음
- SQL 표준은 DBMS 간에 상호 호환성이 뛰어나 다른 시스템으로 이식이 쉬움 - 표준이 계속 발전중
- 질의 후 바로 결과 얻는 대화식 언어이며 쿼리 언어
→ DBMS에 질의를 보내 결과를 받는 방식 - 분산형 클라이언트/서버 구조
- 클라이언트에서 질의
- 서버에서 그 질의를 받아 처리
- 다시 클라이언트에게 전달하는 구조 - 주의할 점
- 모든 DBMS의 SQL문이 완벽하게 동일하지 않음
- 자신의 제품에 특화시킨 SQL이 존재
- 독립성: DBMS 제작 회사와 독립적
- SQL 명령어
- DML(Data Manipulation Language)
- 데이터 조작어로 검색 및 수정 기능 제공
- SELECT, INSERT, UPDATE, DELETE, MERGE
- DDL(Data Definition Language)
- 데이터 구조를 생성, 변경, 삭제 등의 기능을 제공
- CREATE, ALTER, DROP, RENAME
- DCL(Data Control Language)
- 데이터에 대한 권한 관리 및 트랜잭션 제어
- GRANT, REVOKE
- DML(Data Manipulation Language)
- SQL 주요 기능
- 데이터 검색
- 관계형 데이터베이스에서 특정 데이터를 가져올 수 있음 - 데이터 조작(추가/삭제/수정)
- 기존 테이블에 새로운 데이터를 추가, 특정 데이터를 삭제할 수 있음
- 이미 있는 데이터를 수정할 수 있음 - 데이터베이스나 테이블 작성
- 새로운 데이터베이스나 테이블을 작성할 수 있음
- 데이터 검색
- Query 작성 규칙
- 원칙적으로 로마자로 기술
- 주석 및 ' ' 안에서 한글을 쓸 수 있음
- '를 표시할 때는 ''로
- 주석은 /*와 */로 둘러쌈
- 예약어
- SQL에 있어서 특별한 의미를 갖는 키워드
- 테이블명이나 열 이름 등에 사용할 때는 [ ]로 둘러쌈
[120차시]실습: 스키마 및 Table 생성하기

Administration > Users and Privileges > Add Account > Login Name과 Password 설정 후 Apply
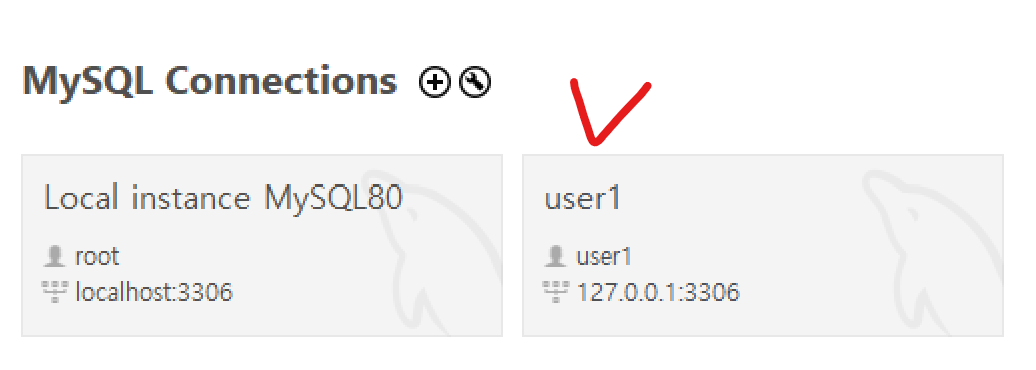
- Administrative Roles > 모든 권한 apply
- Schema Privileges를 통해 특정 스키마에만 권한을 줄 수도 있다
- Add Entry > Selected schema: world
- 원하는 권한 선택 후 apply
show databases;
use world;
show tables;테이블이 잘 추가된 것을 확인할 수 있다.

lecture schema도 생성하였다.
[121차시]DDL 이용 스키마 생성, DML 구문 사용하기
[122차시]실습: DDL 이용 샘플 스키마 생성하기
SHOW 명령
데이터베이스 관련 대부분의 정보를 얻을 수 있음
#데이터베이스 설정 확인
SHOW VARIABLES;
--variables;
#데이터베이스 설정 중에서 "char_"로 시작하는 변수를 확인한다.
SHOW variables like 'char_%';
#스키마 목록
SHOW DATABASES;
SHOW TABLES;
SHOW TABLES FROM lecture;
- SHOW statement
- 어떤 데이터베이스가 있는지 확인
- 데이터베이스 전체 목록 출력 show databases;
- 데이터베이스 전체 테이블 목록 출력 show tables;
DDL 명령
- CREATE: Schema, Table 생성 / 테이블 구조를 신규 생성
[데이터베이스/스키마 생성]


[Table 관련]

예제
CREATE TABLE BookLibrary(
bookid INTEGER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER
);BookLibrary 테이블 생성
→ 정수형: iNTEGER, 문자형: 가변형 문자타입 VARCHAR
데이터 종류

Constraint(제약조건)
- Database 테이블 레벨에서 특정한 규칙을 설정한다
- 예상치 못한 데이터의 손실이나 일관성을 어기는 데이터의 추가, 변경 등을 예방한
- 종류
- NOT NULL
- UNIQUE
- PRIMARY / FOREIGN KEY
- CHECK
- DEFAULT
예제

두가지 방법 모두 가능하다

bookid 같은 단일 값을 갖는 속성이 없다면 두 개 이상의 복합 속성으로 사용한다.
→ bookname, publisher가 기본키가 된다면 괄호를 사용하여 복합키를 지정한다.
CREATE TABLE BookLibrary (
bookname VARCHAR(20) NOT NULL,
publisher VARCHAR(20) UNIQUE,
price INTEGER DEFAULT 10000 CHECK(price > 5000),
PRIMARY KEY (bookname, publisher)
);
- bookname: Null 값을 가질 수없다
- publisher: 중복된 값을 가질 수 없다.
- price에 값이 입력되지 않을 경우 기본값 10000을 저장한다
price는 5000을 초과해야한다.
- ALTER: 테이블 구조를 변경
- 생성된 테이블의 속성과 속성에 관한 제약, 기본키 및 외래키를 변경한다
- ADD, DROP은 속성을 추가/제거할 때 사용한다
- MODIFY는 속성의 기본값을 설정/삭제할 때 사용한다
- ADD/DROP<제약이름>은 제약사항을 추가/삭제할 때 사용한다.

예제
#BookLibrary 테이블에 VARCHAR(30)의 자료형을 가진 inventory 속성을 추가하시오.
ALTER TABLE BookLibrary ADD inventory VARCHAR(30);
#BookLibrary 테이블의 inventory 속성의 데이터 타입을 INTEGER형으로 변경하시오.
ALTER TABLE BookLibrary MODIFY inventory INTEGER;
#BookLibrary 테이블 inventory 속성을 삭제하시오.
ALTER TABLE BookLibrary DROP COLUMN inventory;
DESRIBE 구문: 현재 스키마 안에 있는 테이블의 구성 출력
→ 컬럼 속성 출력

예제


- DROP: 테이블 구조와 데이터를 모두 삭제
※ 데이터만 삭제하려면 DELETE문 사용

- RENAME: 테이블명을 변경
- TRUNCATE: 데이터의 모든 내용을 삭제
DML 명령
- SELECT: 테이블의 레코드에 대한 질의를 통해 row로 결과를 반환

→ MySQL은 전체 row를 출력하고, 마지막에 전체 row 수와 쿼리실행에 걸린 시간을 표시한다.
예제


단일 컬럼: SELECT 구문에 하나의 컬럼 이름만 지정
다중 컬럼 지정: SELECT 구문에 여러 개의 열 이름을 ,로 나열
전체 컬럼 지정: *

예제
#모든 도서의 이름과 가격을 검색
SELECT bookname, price
FROM book;
주석
- 쿼리에 주석을 사용해 설명
- 여러줄 주석은 /* */로 둘러쌈
- 한 줄 주석은 -- 다음에 작성
- INSERT: 테이블에 새로운 레코드를 삽입
- DELETE: 테이블의 특정 조건에 맞는 레코드를 삭제
- UPDATE: 테이블의 레코드의 필드를 갱신
실습 코드
SHOW VARIABLES;
SHOW VARIABLES LIKE 'char_%'; -- char을 포함하는 환경변수 찾기
SHOW DATABASES;
USE WORLD;
SHOW TABLES;
--
DROP DATABASE lecture;
CREATE DATABASE lecture;
USE lecture;
show tables;
-- BookLibrary 테이블을 생성하시오
create table BookLibrary(
bookid integer,
bookname varchar(20),
publisher varchar(20),
price integer
);
drop table BookLibrary;
-- 제약조건
create table BookLibrary(
bookid integer,
bookname varchar(20),
publisher varchar(20),
price integer,
primary key (bookid)
);
create table BookLibrary(
bookid integer primary key,
bookname varchar(20),
publisher varchar(20),
price integer
);
-- 복합키
create table BookLibrary(
bookname varchar(20) not null,
publisher varchar(20) unique,
price integer default 10000 check(price > 5000),
primary key (bookname, publisher)
);[123차시]데이터 추가, 삭제, 갱신
[124차시]실습: INSERT, DELETE, UPDATE사용하기
INSERT
: 테이블에 새로운 레코드(튜플)을 삽입하는 명령

# Book 테이블에 새로운 도서 '스포츠 의학' 삽입
# 스포츠 의학은 한솔의학서적에서 출간했으며 가격은 90,000원이다.
INSERT INTO Book(bookid, bookname, publisher, price)
VALUES(11, '스포츠 의학', '한솔의학서적', 90000);
UPDATE
: 특정 속성 값을 수정하는 명령

MySQL v8 이후 Unsafe Update
update, delete 명령이 아래와 같은 에러를 만날 수 있다.

- 보안문제로 Unsafe한 Update를 방지하고자 기본으로 지정되어있다.
- MySQL v8 이후는 Unsafe Update를 기본적으로 수행하지 못한다.
→ MySQL의 글로벌 환경변수 SET SQL_SAFE_UPDATES를 통해 해지 가능하다
+) my, ini, 환경설정을 통해서도 가능하다.
-- Unsafe Update 호출
UPDATE Booklibrary
SET bookname='대한민국 부산'
-> 모두 변경, 전체 값을 업데이트할 때 유용
-- Unsafe Update 해지
SET SQL_SAFE_UPDATES=0; /* Safe Updates 옵션 미 해제 시 실행 */
-- Customer 테이블에서 고객번호가 5인 고객의 주소를 ‘대한민국 부산’으로 변경하시오.
UPDATE Customer
SET address='대한민국 부산'
WHERE custid=5;
Schema와 Table 구문
스키마 건너 SQL 명령을 수행할 수 있다.
대부분의 SQL구문은 Schema를 . 으로 지정해 작성할 수 있다.
→ 테이블 이름을 Schema.Table_name 형식으로 지시한다.

/* 이름: demo_bookstore.sql */
/* 설명 */
/* root 계정으로 접속, bookstore 데이터베이스 생성, user1 계정 생성 */
/* MySQL Workbench에서 초기화면에서 +를 눌러 root connection을 만들어 접속한다. */
-- DROP DATABASE IF EXISTS bookstore;
-- DROP USER IF EXISTS user1@localhost;
-- create user user1@localhost identified WITH mysql_native_password by '012345';
-- create database bookstore;
-- grant all privileges on user1.* to user1@localhost with grant option;
-- commit;
/* 자료 생성 */
USE bookstore;
CREATE TABLE Book (
bookid INTEGER PRIMARY KEY,
bookname VARCHAR(40),
publisher VARCHAR(40),
price INTEGER
);
CREATE TABLE Customer (
custid INTEGER PRIMARY KEY,
username VARCHAR(40),
address VARCHAR(50),
phone VARCHAR(20)
);
CREATE TABLE Orders (
orderid INTEGER PRIMARY KEY,
custid INTEGER ,
bookid INTEGER ,
saleprice INTEGER ,
orderdate DATE,
FOREIGN KEY (custid) REFERENCES Customer(custid),
FOREIGN KEY (bookid) REFERENCES Book(bookid)
);
--Inser Bulk
INSERT INTO Book VALUES(1, '철학의 역사', '정론사', 7500);
INSERT INTO Book VALUES(2, '3D 모델링 시작하기', '한비사', 15000);
INSERT INTO Book VALUES(3, 'SQL 이해', '새미디어', 22000);
INSERT INTO Book VALUES(4, '텐서플로우 시작', '새미디어', 35000);
INSERT INTO Book VALUES(5, '인공지능 개론', '정론사', 8000);
INSERT INTO Book VALUES(6, '파이썬 고급', '정론사', 8000);
INSERT INTO Book VALUES(7, '객체지향 Java', '튜링사', 20000);
INSERT INTO Book VALUES(8, 'C++ 중급', '튜링사', 18000);
INSERT INTO Book VALUES(9, 'Secure 코딩', '정보사', 7500);
INSERT INTO Book VALUES(10, 'Machine learning 이해', '새미디어', 32000);
INSERT INTO Customer VALUES (1, '박지성', '영국 맨체스타', '010-1234-1010');
INSERT INTO Customer VALUES (2, '김연아', '대한민국 서울', '010-1223-3456');
INSERT INTO Customer VALUES (3, '장미란', '대한민국 강원도', '010-4878-1901');
INSERT INTO Customer VALUES (4, '추신수', '대한민국 부산', '010-8000-8765');
INSERT INTO Customer VALUES (5, '박세리', '대한민국 대전', NULL);
INSERT INTO Orders VALUES (1, 1, 1, 7500, STR_TO_DATE('2021-02-01','%Y-%m-%d'));
INSERT INTO Orders VALUES (2, 1, 3, 44000, STR_TO_DATE('2021-02-03','%Y-%m-%d'));
INSERT INTO Orders VALUES (3, 2, 5, 8000, STR_TO_DATE('2021-02-03','%Y-%m-%d'));
INSERT INTO Orders VALUES (4, 3, 6, 8000, STR_TO_DATE('2021-02-04','%Y-%m-%d'));
INSERT INTO Orders VALUES (5, 4, 7, 20000, STR_TO_DATE('2021-02-05','%Y-%m-%d'));
INSERT INTO Orders VALUES (6, 1, 2, 15000, STR_TO_DATE('2021-02-07','%Y-%m-%d'));
INSERT INTO Orders VALUES (7, 4, 8, 18000, STR_TO_DATE( '2021-02-07','%Y-%m-%d'));
INSERT INTO Orders VALUES (8, 3, 10, 32000, STR_TO_DATE('2021-02-08','%Y-%m-%d'));
INSERT INTO Orders VALUES (9, 2, 10, 32000, STR_TO_DATE('2021-02-09','%Y-%m-%d'));
INSERT INTO Orders VALUES (10, 3, 8, 18000, STR_TO_DATE('2021-02-10','%Y-%m-%d'));
select * from book;
select * from customer;
select * from orders;[125차시]Where 조건 지정과 논리, 비교연산자, 패턴 매칭 이해
[126차시]실습: where 조건절 사용
WHERE구문
테이블 질의 시 조건을 지정함
→ 질의 결과에 필터를 건다

- 비교, 조건 등의 연산을 사용하거나 복합문으로 사용 가능

-- 우편번호가 340-011 인 사람을 출력하시오.
SELECT name
FROM shopper
WHERE zip_code = '340-021';
-- 주문액이 20000에서 30000 인 사람을 출력하시오.
SELECT name
FROM shopper
WHERE total BETWEEN 20000 AND 30000;
-- 주문액이 20000 이상인 사람을 출력하시오.
SELECT name
FROM shopper
WHERE total >= 20000;
LIKE절
: 쿼리 결과가 LIKE에 일치하는 결과만을 제공

- LIKE 절에 연산기호(와일드카드 문자열)를 사용하면 일치하는 조건 지정 가능

-- '철학의 역사'를 출간한 출판사를 검색하시오.
SELECT bookname, publisher
FROM Book
WHERE bookname LIKE '철학의 역사';
-- 도서이름에 '파이썬’이 포함된 출판사를 검색하시오.
SELECT bookname, publisher
FROM Book
WHERE bookname LIKE '%파이썬%';
NULL
- 아직 지정되지 않은 값
- 0, 빈 문자, 공백과 다른 특별한 값
- NULL값은 비교 연산자로 비교 불가능
- NULL값의 연산을 수행하면 결과 역시 NULL 값으로 반환됨
집계 함수 사용할 때 주의할 점
- NULL + 숫자 = NULL
- 집계 함수 계산 시 NULL 이 포함된 행은 집계에서 빠짐
- 해당되는 행이 하나도 없을 경우 SUM, AVG 함수의 결과는 NULL이 되며, COUNT 함수의 결과는 0이

-- NULL인 문자열 결합
SELECT CONCAT("전화번호: ", phone )
FROM customer;
NULL값과 데이터를 concat하면 NULL이 출력된다.
[127차시]LIMIT, ORDER BY, CASE 구문 통한 조건 제어
[128차시]실습: where 조건의 논리적 처리
ORDER BY 구문
쿼리 결과를 주어진 컬럼의 오름차순, 내림차순으로 정렬해 출력

- 정렬 조건
| 연산자 | 설명 |
| ASC | 오름차순으로 정렬 |
| DESC | 내림차순으로 정렬 |
-- 도서를 이름순으로 검색하시오.
SELECT *
FROM Book
ORDER BY bookname;
-- 도서를 가격순으로 검색하고, 가격이 같으면 이름순으로 검색
SELECT *
FROM Book
ORDER BY price, bookname;
- 오름차순/내림차순 지시
SELECT *
FROM Book
ORDER BY price DESC, publisher ASC;
SELECT *
FROM orders
ORDER BY orderdate DESC;- 조건식과 정렬 결합
-- 판매가격이 1000 이상인 결과를 도서번호로 출력하시오
SELECT *
FROM orders
WHERE saleprice > 1000
ORDER BY bookid;- 컬럼 번호로 지시 가능
-- 컬럼번호 1번, 3번 순서로 정렬
SELECT *
FROM Book
ORDER BY 1, 3;
DISTINCT 구문
: 조회된 결과에서 중복된 데이터를 제외하고 출력

- bookstore 테이블에서 중복 데이터를 제외해보기
-- 주문 고객목록
SELECT DISTINCT custid
FROM orders;
-- 판매가격 목록
SELECT DISTINCT saleprice
FROM orders;
-- 주문이 있는 고객의 숫자
SELECT count(DISTINCT custid)
FROM orders;
조건제어
다중 조건을 제공하는 CASE 구문
: 조회된 결과에서 중복된 데이터 제외하고 출력
→ CASE는 내장 함수는 아니며 연산자(Operator)로 분류

- WHEN과 THEN은 한쌍이어야 한다.
- WHEN과 THEN은 다수가 존재할 수 있다.
- ELSE가 존재하면 모든 조건에 해당하지 않는 경우에 반환 값을 설정할 수 있다.
- ELSE가 존재하지 않고, 조건에 맞지 않아서 반환 값이 없으면 NULL을 반환한다.
SELECT custid, SUM(saleprice) AS '총구매액',
CASE
WHEN (saleprice >= 15000) THEN '최우수고객',
WHEN (saleprice >= 10000) THEN '우수고객',
WHEN (saleprice >= 5000) THEN '일반고객',
ELSE '유령고객'
END AS '고객등급'
FROM Orders O
GROUP BY custid;
조건 제어를 위한 IF 구문
: 참/거짓으로 2중 분기

IFNULL(수식1, 수식2)

LIMIT문
- SELECT로 받아온 결과(레코드)의 출력 개수를 제한하고자 할 때, SQL 문장의 제일 마지막에 사용
- LIMIT n: 첫번째 행부터 n개를 출력
- LIMIN s, n: s번째 행부터 n개를 출력 (s개의 행을 SKIP)
SELECT first_name, salary
FROM employees
ORDER BY salary DESC
LIMIT 3;
SELECT first_name, salary
FROM employees
ORDER BY salary DESC
LIMIT 10, 3;마무리하며
주피터 노트북을 HTML로 가져온 후 기본모드로 변경하면 서식이 다 깨져버려서 글을 수정하기가 힘들었는데 방법을 찾았다! 새로운 파일을 하나 만들어서 맨 위에 추가하면된다. 글을 모두 작성한 후 맨 위에 임의의 주피터 노트북 html을 가져오면 밑에 서식이 깨졌던 부분들도 원래대로 돌아온다 🎉

SQL은 Oracle로만 공부해보고 MySQL은 처음 사용해보는데 사용법이 조금 복잡한 것 같다😵💫 강의 듣는 시간도 오래걸렸다..ㅎㅎ 그래도 기본 문법들은 코딩테스트 준비하며 봤던 것들이라 따라가는데 크게 어려운 부분은 없었다! 내일부터는 조금 어려운 내용에 들어가기도 하고 MySQL은 오라클과 문법도 다르다고 해서 열심히 들어야겠다💪
파트너간 상보적 학습 및 강의 내용 리뷰
파이썬은 전처리 부분만 강의에 있었고, 이야기를 나눌 때에는 SQL 또한 본격적인 실습에 들어가기 이전이라서 강의에 대한 질문은 따로 없었다! SQL은 강의 듣는게 오래 걸려서 남는 시간에는 강의를 마저 수강했다.
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 10일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.17 |
|---|---|
| [👩💻TIL 9일차 ] 유데미 스타터스 취업 부트캠프 4기 (2) | 2023.02.16 |
| [👩💻TIL 7일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.14 |
| [👩💻TIL 6일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.13 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 1주차 학습 일지 (0) | 2023.02.10 |



