
홍동이의 성장일기
[👩💻TIL 9일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
[137차시]테이블 관계 조인(INNER, OUTER) 이해하기
[129차시]내장함수, 수치/문자열 연산자 사용하기
[130차시]실습: 문자/수치 자료형과 내장함수
산술 연산자
: SQL에서 숫자 리터럴에 사용할 수 있는 연산자

-- book 테이블의 price 에 0.05를 곱한다.
SELECT price*0.05
FROM book;
-- book 테이블의 price를 2로 나누고 결과에 100을 곱한다.
SELECT (price/2)*100
FROM book;
비교 연산자
: SQL 비교 리터럴 및 WHERE 절의 값의 비교에 사용하는 연산자
- 비교 연산자 사용시 연산 결과 조건이 성립한 경우
참: 1, 거짓: 0 반환

논리 연산자
: 여러 리터럴 조건을 조합해 복합 조건을 나타낼 수 있다
- 참: 1, 거짓: 0 반환

내장 함수
: DBMS에서 자주 사용하는 기능을 제공하는 것
- 쿼리에 내장함수를 활용해 질의할 수 있음
sum, count, average등


위와 같은 함수를 "집계함수"라고 한다.
- 집계함수는 SELECT절이나 HAVING절에서만 호출된다.
- SELECT절에 집계함수를 사용했다면 또다른 열을 함께 호출할 수 없다.
→ GROUP BY를 사용해야함
| 내장함수 | 문법 |
| POWER | POWER(숫자, 제곱) |
| ROUND | ROUND(값, 소수점) |
| MOD | MOD(값, 값) |
| CEIL, FLOOR |
💡dual table은 시스템에서 제공하는 가상의 테이블로, 함수 등을 쿼리로 계산 시 사용
-- 북스토어의 도서 판매 건수를 구하시오.
SELECT COUNT(*)
FROM Orders;
-- 고객이 주문한 도서의 총 판매액, 평균값, 최저가, 최고가을 구하시오.
select sum(saleprice) total,
avg(saleprice) average,
min(saleprice) minimum,
max(saleprice) maximum
from orders;※ 내장함수 결과 출력 시 컬럼 이름이 내장함수 이름으로 나타나는데, 이는 Alias의 AS절로 정리할 수 있다.

ALIAS
- SQL 구문에서 대상을 다른 이름으로 사용함
- Column Alias: AS 절을 붙여 컬럼 이름을 사용함
- Table Alias: 테이블 이름 뒤에 Alias 이름을 사용함
- 쿼리의 맨 마지막에 실행된다. (= WHERE 연산자나 GROUP BY 호출에서는 별칭을 필터로 사용할 수 없음. 원래 열이름을 사용해야 한다.)

-- 고객이 주문한 도서의 총 판매액을 '총매출' 로 구하시오.
SELECT SUM(saleprice) AS 총매출
FROM Orders;
-- 고객이 주문한 도서의 총 판매액을 '총매출' 로 구하시오.
SELECT AVG(saleprice) AS 매출평균
FROM Orders;※ 의미있는 열 이름을 출력하고 싶으면 속성이름의 별칭을 지정하는 AS 키워드를 사용하여 열 이름을 부여
문자열 다루기
결합 함수
: 컬럼과 문자열, 문자열과 문자열을 결합함

-- 문자열 결합
SELECT CONCAT("도서명: ", bookname)
FROM book;
문자열 결합 함수
: 문자열과 문자열을 결합함

SELECT concat('홍길동', '모험');
SELECT concat_ws(',', '홍길동', '모험');
-- 아래와 비교해 보자
SELECT '홍길동','모험'; -- 컬럼이 나눠짐

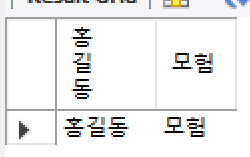
-- book 테이블에서 도서이름과 출판사를 ':' 로 연결해 출력
SELECT CONCAT_WS(":", bookname, publisher)
FROM book;
-- 아래와 비교해 보자
SELECT bookname, ":", publisher
FROM book;

-- customer 의 name과 phone을 ':' 로 묶어 보자
SELECT GROUP_CONCAT(username, ":", phone) AS "전화"
FROM customer;
-- 위 결과와 비교해 보자.
SELECT concat_ws(':', username, phone) AS '전화'
FROM customer;

문자열 길이 함수

공백 제거 함수
-- TRIM() - 문자열 좌우 공백 제거
SELECT TRIM(' 안녕하세요 ');
-- LTRIM() – 좌측 공백 제거
SELECT LTRIM(' 안녕하세요');
-- RLTRIM 우측 공백 제거
SELECT RTRIM('안녕하세요 ');
-- 문자열 좌측 문자 제거 (LEADING)
SELECT TRIM(LEADING '얍' FROM '얍안녕하세요');
-- 문자열 우측 문자 제거 (TRAILING)
SELECT TRIM(TRAILING '얍' FROM '안녕하세요얍')
문자 개수 함수
: Byte 단위 개수와 문자 개수 함수를 구분해야 함
-- Byte 단위
SELECT LENGTH('Hello'); --5
-- 문자 단위
SELECT CHAR_LENGTH('Hello'); --5
SELECT CHARACTER_LENGTH('Hello'); --5
-- Byte 단위
SELECT LENGTH('안녕'); --6
-- 문자 단위
SELECT CHAR_LENGTH('안녕'); --2
SELECT CHARACTER_LENGTH('안녕')
대/소문자 변환 함수
: 알파벳 문자를 대/소문자로 변환할 수 있음

문자열 추출 함수

-- 안녕하세요 문자열에서 2~3 번 인덱스 문자를 추출
select substring('안녕하세요', 2,3); -- 녕하세
-- 안.녕.하.세.요 문자열에서 . 를 만난후 2번째 까지
select substring_index('안.녕.하.세.요', '.', 2); -- 안.녕
-- 안.녕.하.세.요 문자열에서 . 를 만난후 뒤에서 -3번째 까지
select substring_index('안.녕.하.세.요', '.', -3); -- 하.세.요
SELECT LEFT('안녕하세요', 3); -- 안녕하
SELECT RIGHT('안녕하세요', 3); -- 하세요[131차시]날짜 데이터 형식과 연산 사용하기
[132차시]실습: 날짜 데이터 처리하기
MySQL에서 지원하는 자료형
- Numeric

- Date and Time

- String


- Spatial
- JSON
- Geo
- 기타
날짜 자료형 다루기
날짜 데이터에서 일, 열, 연도 구하기
- YEAR, MONTH, DAY, LAST_DAY (날짜)
- HOUR, MINUTE, SECOND, MICROSECOND (시간)

현재 날짜
- CURDATE, CURTIME: 오늘 날짜를 YYYY-MM-DD나 YYYYMMDD 형식으로 반환
- NOW, SYSDATE: 현재 시간을 YYYY-MM-DD HH:MM:SS 형식으로 반환



날짜/시간 증감 함수



날짜/시간 사이의 차이와 월/요일/주 값





자료형 변환 함수
데이터 형식 변환 함수

MySQL의 데이터형식
- BINARY
- CHAR
- DATE
- DATETIME
- TIME
- SIGNED {INTEGER}
- UNSIGNED {INTEGER}
-- 구매 테이블 에서 평균 구매 개수를 구한다.
SELECT AVG(saleprice) AS '평균 구매 가격'
FROM orders;
-- 구매 가격을 정수로 출력한다
SELECT CAST(AVG(saleprice) AS SIGNED INTEGER) AS '평균 구매 가격'
FROM orders;
SELECT CONVERT(AVG(saleprice), SIGNED INTEGER) AS '평균 구매 가격'
FROM orders;

→ CAST 함수에 다양한 구분자($, /, %, @)를 날짜 형식으로 사용할 수 있다.
날짜/시간 데이터 형식

암묵적 형변환
: CAST함수나 CONVERT 함수를 사용하지 않고 데이터 형식을 변환하는 것



-- 현재 날짜/시간 함수
SELECT NOW(),SYSDATE(),CURRENT_TIMESTAMP;
SELECT CURTIME(), CURRENT_TIME;
-- 날짜 시간 증감 함수
SELECT ADDDATE('2021-8-31', INTERVAL 5 DAY), ADDDATE('2021-8-31', INTERVAL 1 MONTH);
SELECT ADDTIME('2021-01-01 23:59:59', '1:1:1'), ADDTIME('09:00:00', '2:10:10');
-- "예" 날짜/시간 사이의 차이
SELECT DATEDIFF('2022-01-01', NOW());
SELECT TIMEDIFF('23:23:59', '2:1:1');
-- 날짜/시간 생성
SELECT MAKEDATE(2021, 55);
SELECT DATE_FORMAT(MAKEDATE(2021, 55),'%Y.%m.%d');
SELECT MAKETIME(11, 11, 10); # hh:mm:ss
SELECT QUARTER('2021-04-04'); # 2
/* 자료형 변환 함수 */
USE BOOKSTORE;
-- 데이터 형식 변환 함수
-- 구매 테이블 에서 평균 구매 개수를 구한다.
SELECT AVG(saleprice) AS '평균 구매 가격' FROM orders;
-- 구매 가격을 정수로 출력
SELECT CAST(AVG(saleprice) AS SIGNED INTEGER)
AS '평균 구매 가격' FROM orders;
--
SELECT CONVERT(AVG(saleprice), SIGNED INTEGER) AS '평균 구매 가격' FROM orders;
-- 데이터 형식 변환 함수
-- CAST( ) 함수에 다양한 구분자($, /, %, @)를 날짜 형식으로 사용할 수 있다.
SELECT CAST('2021$09$20' AS DATE) AS '날짜';
SELECT CAST('2021/09/20' AS DATE) AS '날짜';
SELECT CAST('2021%09%20' AS DATE) AS '날짜';
SELECT CAST('2021@09@20' AS DATE) AS '날짜';
-- Date and Time Data Types
-- 날짜 데이터 형식과 시간 데이터 형식
SELECT CAST('2020-10-19 12:35:29.123' AS DATE)
AS 'DATE';
SELECT CAST('2020-10-19 12:35:29.123' AS TIME)
AS 'TIME';
SELECT CAST('2020-10-19 12:35:29.123' AS DATETIME)
AS 'DATETIME';
-- 암묵적 형 변환: 연산의 결과에 따른 규칙
SELECT '100' + '200'; -- 문자와 문자를 더함(정수로 변환한 후 처리)
SELECT CONCAT('100', '200'); -- 문자와 문자를 연결(문자열 그대로 처리)
SELECT CONCAT(100, '200'); -- 정수와 문자를 연결(정수를 문자로 변환하여 처리)
SELECT 1 > '3mega'; -- 정수인 3으로 변환한 후 비교
SELECT 4 > '3MEGA'; -- 정수인 3으로 변환한 후 비교
SELECT 0 = 'mega3'; -- 문자가 0으로 변환됨
--
-- 현재시간을 날짜로
SELECT CAST(now() AS DATE);
SELECT CAST("123" AS UNSIGNED);
-- 바로 앞의 SELECT 문에서 조회된 행의 개수를 반환
SELECT * FROM ORDERS;
SELECT FOUND_ROWS();
-- 현재 날짜시간 조회
SELECT CURRENT_TIMESTAMP;
SELECT NOW(); # 2021-03-07 오후 9:27:21
SELECT SYSDATE(); #2021-03-07 오후 9:27:21
SELECT CURDATE(); #2021-03-07 오전 12:00:00
-- 현재 날짜형식을 출력
SELECT DATE_FORMAT(CURDATE(),'%Y-%m-%d');
SELECT DATE_FORMAT(CURDATE(),'%d-%m, %Y');
SELECT DATE_FORMAT(CURDATE(),'%d-%m, %Y');
-- ORDERDATE 컬럼 를 특정 형식(format)의 문자열로 변환하여 반환하기
SELECT ORDERDATE FROM ORDERS;
SELECT DATE_FORMAT(CURDATE(),'%Y-%m-%d');
/* 데이터 형식 변환 함수 */
-- 문자열 날짜 데이터 형식을 DATE 형식으로
SELECT CAST('2021-02-19 10:11:40' AS DATE)
AS 'DATE';
-- 문자열 시간 데이터 형식 DATETIME, TIME 형식으로
SELECT CAST('2021-02-19 10:11:40' AS TIME)
AS 'TIME';
SELECT CAST('2021-02-19 10:11:40' AS DATETIME)
AS 'DATETIME';
-- CAST 와 $,%,@ 이용 날짜형 생성
SELECT CAST('2021$09$20' AS DATE) AS '날짜' ;
SELECT CAST('2021/09/20' AS DATE) AS '날짜';
SELECT CAST('2021%09%20' AS DATE) AS '날짜';
SELECT CAST('2021@09@20' AS DATE) AS '날짜';
-- ORDERDATE 컬럼
SELECT * FROM ORDERS;
SELECT CAST(ORDERDATE AS DATETIME) FROM ORDERS;
-- 현재시간을 날짜로
SELECT now(); # YYYY-MM-DD hh:mm:ss 형식
SELECT CAST(now() AS DATE);
-- 날짜 및 시간 더하기/빼기
-- 기준날짜로부터 하루 뒤 날짜 조회
SELECT DATE_ADD("2021-03-07 23:59:59", INTERVAL 1 DAY);
-- 한시간 전
SELECT NOW(),DATE_ADD(NOW(), INTERVAL -1 MONTH) AS 한달전;
SELECT NOW(),DATE_ADD(NOW(), INTERVAL -1 DAY) AS 하루전;
SELECT NOW(),DATE_ADD(NOW(), INTERVAL -1 HOUR) AS 한시간전;
-- ORDERS 테이블에서 주문일자의 한달 날짜 계산
-- SELECT ORDERDATE FROM ORDERS WHERE ORDERDATE >= DATE_ADD(NOW(), INTERVAL -1 MONTH);
SELECT ORDERDATE, DATE_ADD(ORDERDATE, INTERVAL -1 MONTH) FROM ORDERS;
SELECT ORDERDATE, DATE_ADD(ORDERDATE, INTERVAL -1 DAY) FROM ORDERS;
-- ORDERS 테이블에서 주문일자의 하루 전 조회
SELECT CUSTID, ORDERDATE, DATE_ADD(ORDERDATE, INTERVAL -1 DAY) AS 하루전
FROM ORDERS WHERE ORDERDATE >= DATE_ADD(ORDERDATE, INTERVAL -1 DAY);
-- 쿼터
SELECT QUARTER(ORDERDATE) FROM ORDERS; # 2
SELECT QUARTER(DATE_ADD(ORDERDATE, INTERVAL + 3 MONTH)) AS 분기
FROM ORDERS; # 2[133차시]서브쿼리, 인라인뷰
[134차시]실습: 서브쿼리와 집계함수 사용
서브쿼리
: 쿼리문 안에 또 다른 쿼리문이 포함된 구문
※ where 절은 데이터를 불러오는 기능이 없기 때문에 집계 함수를 사용하기 위해서는 서브쿼리를 사용해야 한다.
→ 리턴하는 행과 열의 개수에 따라 분류할 수 있다.
- 단일행 서브쿼리: 하나의 스칼라 값을 반환
- 다중행 서브쿼리: 여러 개의 row를 반환
- 다중행 열 서브쿼리: 여러 개의 column으로 구성된 여러 개의 row인 테이블 반환
서브쿼리의 확장성
: SELECT의 기본 질의는 아주 짧은 단문만 가능하다
실생활의 질문 이보다 복잡해 여러 단계의 질문을 한꺼번에 하는 경우가 많다.
SQL 쿼리에서 복잡한 질의를 수행하는 방법이 서브쿼리이다.
서브쿼리는 WHERE절 안에서도 사용할 수 있다.
-- 제품 판매 가격이 평균보다 큰 제품은?
SELECT * FROM product
WHERE price >= (SELECT avg(price) FROM product);
- 서브 쿼리를 실행: 평균 가격을 산출
- 메인 쿼리를 실행: 평균 가격 이상인 데이터만 가져와서 표시
- 서브쿼리가 집계함수로 인해 단독값으로 도출되면 비교 오퍼레이터를 쓸 수 있지만, 다양한 값으로 도출된다면 IN 오퍼레이터를 써야한다.
상관 부속질의(correlated subquery)
: 상위 부속질의의 튜플을 이용하여 하위부속질의를 계산함
즉, 상위 부속질의와 하위 부속질의가 독립적이지 않고 서로 관련을 맺고 있음
-- 출판사별로 출판사의 평균 도서 가격보다 비싼 도서를 구하시오.
SELECT b1.bookname, price
FROM Book b1
WHERE b1.price > (SELECT avg(b2.price)
FROM Book b2
WHERE b2.publisher=b1.publisher);
Inline View
From 절에서 서브쿼리 사용하기
- FROM절 안에 쓴 서브 쿼리의 결과는 뷰처럼 취급
- 인라인 뷰(Inline View)라고도 한다.
-- subquery 결과를 from 에 사용
SELECT min(price) -- subquery - from
FROM (SELECT * FROM product where price >= 2000) as c_price ;
- 서브쿼리를 실행
- 메인쿼리를 실행
[135차시]GROUP BY와 집계함수 사용
[136차시]실습: 서브쿼리로 그룹화 하기
집계 함수

COUNT
: *을 사용하면 null을 포함한 총 row의 개수를 구하며, 필드를 명시할 경우 null 값을 제외한다.

AVG
-- 평균 구매 가격을 조회
SELECT AVG(saleprice)
FROM Orders;
-- null 값이 있는 경우 IFNULL, COALEACE 함수을 사용해 Default 값을 정해놓는 것이 안전함
select count(*), sum(saleprice), avg(ifnull(saleprice,0))
from orders;
SUM
-- 도서 판매액의 합계
SELECT SUM(saleprice)
FROM Orders;
-- 고객이 주문한 도서의 총 판매액을 구하시오.
SELECT SUM(saleprice) AS 총매출
FROM Orders;
복합 집계 함수 SUM, AVG, MIN, MAX
-- 102번 고객이 주문한 도서의 총 판매액을 구하시오.
SELECT SUM(saleprice) AS 총매출
FROM Orders
WHERE custid=102;
-- 고객이 주문한 도서의 총 판매액, 평균값, 최저가, 최고가를 구하시오.
SELECT SUM(saleprice) AS 총매출,
AVG(saleprice) AS 평균,
MIN(saleprice) AS 최소값,
MAX(saleprice) AS 최대값
FROM Orders;
GROUP BY 절
: GROUP BY에 지정한 열의 같은 데이터 행을 하나로 묶음
➡️ SELECT 그룹으로 묶을 열/카테고리, 집계 함수
- GROUP BY 순서는 중요하지 않다.
→ 대부분의 경우 SELECT문과 GROUP BY문의 순서를 동일하게 지정한다. - DATE 함수: 타임스탬프 정보 중 날짜 부분만 추출한다.
-- 고객마다 주문한 도서의 총 수량과 총 판매액을 구하시오.
select custid, count(*) '도서수량', sum(saleprice) '판매액'
from orders
group by custid;
HAVING 절
: GROUP BY에 선택한 컬럼의 조건을 HAVING 절에 제시한다
= 집계가 수행된 이후에 집계된 결과를 바탕으로 필터링한다.
※ WHERE문에는 집계 함수를 입력해서는 안된다.
➡️ 결과를 필터링하기위해서는 HAVING을 사용해야 한다.
select custid, count(*) '도서수량'
from orders
where saleprice >= 5000
group by custid
having count(*) >= 2;
GROUP BY와 HAVING 사용 시 주의사항
- GROUP BY로 컬럼을 그룹으로 묶은 후, SELECT 절에는 반드시 GROUP BY에서 사용한 컬럼과 집계함수만 나올 수 있음 (primary key는 괜찮다)
- HAVING절은 반드시 GROUP BY절과 같이 작성해야 하고 WHERE절보다 뒤에 나와야 함. 검색조건에는 집계함수가 와야함
- 검색 조건에는 집계함수가 와야한다.
[137차시]테이블 관계 조인(INNER, OUTER) 이해하기
[138차시]실습: 다양한 조인 작성하기
JOIN
: 두 개 이상 테이블에서 SQL 질의
- 여러 테이블을 결합해 질의해서 결과 집합을 도출해낸다.

조인 다이어그램

- 일반조인: SQL문에서는 주로 동등조인을 사용함
- 외부조인: FROM절에 조인 종류를 적고 ON을 이용하여 조인조건을 명시함

일반(INNER) 조인
: 기준 테이블과 중복되는 데이터를 추출
-- 1
select *
from customer c, orders o
where c.custid = o.custid
order by c.custid;
-- 2
select *
from customer c join orders o
where c.custid = o.custid
order by c.custid;

- 두 테이블에서 열 이름을 공유한다면 해당 열을 참조하는 테이블이 어떤 것인지 지정해야 한다.
- group by를 함께 사용할 수 있다.
select username, sum(saleprice)
from customer c, orders o
where c.custid = o.custid
group by c.custid
order by c.custid;
외부조인
: 상대 테이블과 결합된 집합이 된다.
- FULL OUTER JOIN (합집합): 전부 선택한 후 한 테이블에만 존재하는 행에는 NULL값을 입력
- WHERE문으로 둘 중 하나의 테이블에 고유한 행을 구할 수 있다. (↔ INNER JOIN)
➡️ WHERE TableA.id IS null OR TableB.id IS null
- WHERE문으로 둘 중 하나의 테이블에 고유한 행을 구할 수 있다. (↔ INNER JOIN)
- LEFT OUTER JOIN
- WHERE문으로 A의 고유한 항목만 구하기
➡️ WHERE TableB.id IS null
- WHERE문으로 A의 고유한 항목만 구하기
- RIGHT OUTER JOIN
- WHERE문으로 B의 고유한 항목만 구하기
➡️ WHERE TableA.id IS null
- WHERE문으로 B의 고유한 항목만 구하기
select c.username, o.saleprice
from customer c left outer join orders o
on c.custid = o.custid;
- CROSS JOIN (상호 조인) : 테이블의 모든 행들과 조인 대상 테이블의 모든 행을 조인시키는 기능이다.

-- 1
select c.username, o.saleprice
from customer c cross join orders o;
-- 2
select c.username, o.saleprice
from customer c, orders o;
[실습코드]
-- 일반조인: 동등조인, INNER JOIN
-- 조건문과 정렬을 함께 사용해 보자.
-- 고객 이름, 고객 주문 도서의 판매 가격을 출력
SELECT username, saleprice
FROM CUSTOMER C, ORDERS O
WHERE C.custid = O.custid;
-- INNER JOIN
SELECT username, saleprice
FROM CUSTOMER C JOIN ORDERS O
ON C.custid = O.custid;
-- 도서 가격이 20000원인 이상인 도서를 주문한 고객의 이름, 주문 도서 이름을 출력
SELECT C.username AS '이름', B.bookname AS '도서명'
FROM CUSTOMER C, ORDERS O, BOOK B
WHERE C.custid = O.custid
AND O.bookid = B.bookid
AND B.price >= 20000;
-- GROUP 을 함께 사용할 수 있다.
-- 고객 별로 주문 도서의 총 판매액, 고객이름을 주문일자로 정렬
SELECT username, SUM(saleprice)
FROM CUSTOMER C, ORDERS O
WHERE C.custid = O.custid
GROUP BY C.username
ORDER BY O.orderdate;
-- 고객의 이름, 주문 도서 이름을 출력.
SELECT C.username as '이름', B.bookname AS '도서명'
FROM CUSTOMER C, ORDERS O, BOOK B
WHERE C.custid = O.custid
AND O.bookid = B.bookid;
-- 외부조인
-- 도서를 구매하지 않은 고객을 포함해 고객 이름/전화번호 와 주문 도서의 판매 가격을 출력
SELECT C.username, C.phone, O.saleprice
FROM CUSTOMER C
LEFT OUTER JOIN ORDERS O
ON C.custid = O.custid;
/* Cross Join */
-- 상호 존재하는 행을 모두 반환, 많은쪽 행 수 만큼 반환
SELECT count(*) FROM ORDERS;
SELECT count(*) FROM customer;
-- 도서를 구매한 이력이 있는 고객 이름, 판매 도서의 가격을 출력하세요.
SELECT Customer.username, saleprice, orderdate
FROM Customer
CROSS JOIN ORDERS
ON Customer.custid = ORDERS.custid;[139차시]조인과 집합 연산자 사용하기
집합 연산자
:두 개의 SELECT 문의 결과에 합집합, 교집합, 차집합을 구하는 연산자
- 결합하는 SELECT문의 결과는 열의 수나 각각의 데이터형이 똑같아야 한다.
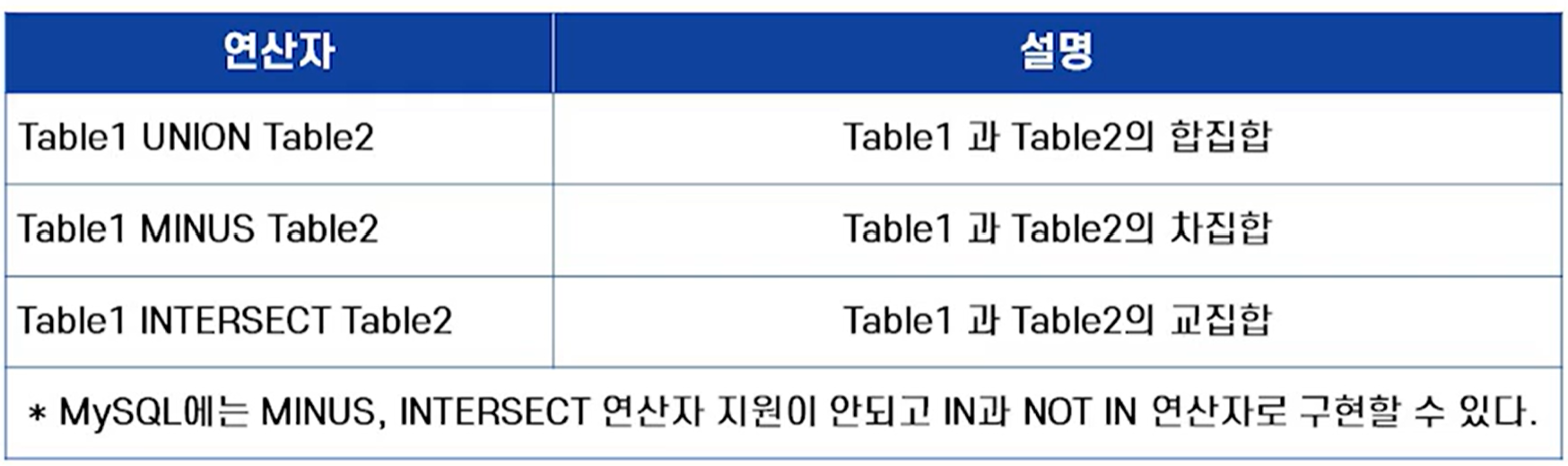
합집합 UNION
: 중복되는 데이터를 정리한 후 가져온다.
- 두 문장이 논리적이어야 한다.
- 서로의 바로 위에 결과를 쌓을 수 있도록 열이 일치해야 한다.
select username, address
from customer
where address like '대한민국%'
union
select username, address
from customer
where custid in (select custid from orders);
MINUS & INTERSECT 연산자
- MySQL에는 MINUS, INTERSECT 연산자를 지원하지 않는다.
- MINUS를 NOT IN, INTERSECT를 IN 서브쿼리로 사용 가능하다.
/* MINUS 대체, NOT IN */
-- 대한민국 거주 고객의 이름에서 도서를 주문 고객의 이름 제외하고 출력.
-- 주문과 고객 테이블에서 도서를 주문하지 않은 고객만 조회하자
SELECT username, address
FROM Customer
WHERE address LIKE '대한민국%'
AND username NOT IN (SELECT username
FROM Customer
WHERE custid IN (SELECT custid FROM Orders));
/* INTERSECT 대체, IN */
SELECT username, address
FROM Customer
WHERE address LIKE '대한민국%'
AND username IN (SELECT username
FROM Customer
WHERE custid IN (SELECT custid FROM Orders));

다중행 연산자
- 다중 행 연산자는 하나 이상의 값을 필요로 한다.
- 메인쿼리와 서브쿼리 사이의 다중행 반환 값에 대한 비교를 수행한다.
- 비교연산자(<, >, =, <>)와 결합해서 사용한다.

※ NOT EXISTS는 부속질의문의 모든 행이 조건에 만족하지 않을 때만 참이다.
IN
-- 주문 테이블에 25000원 이상 주문한 고객의 이름, 주소, 책제목
select *
from customer c, orders o, book b
where c.custid = o.custid
and o.bookid = b.bookid
and o.orderid in (select orderid from orders where saleprice >= 25000);
NOT IN
-- 도서를 주문하지 않은 고객 id, 이름 추출
#1. 도서를 주문한 고객 추출
select custid from orders;
#2. 모든 고객에서 도서를 주문한 고객 제외
select custid
from customer
where custid not in (select custid from orders);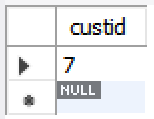
EXISTS
-- 주문 이력이 있는 고객의 이름, 주소 출력
select username, address
from customer c
where exists (select * from orders o where c.custid = o.custid);
ANY
select bookname, publisher, price
from book
where price = any (select saleprice
from orders
where saleprice between 5000 and 20000);
[140차시]실습: 다양한 집합 연산자 사용하기
/* 집합연산자 */
-- UNION
-- 도서 주문에서 고객 주소가 서울인 고객의 이름, 전화번호를 출력하자.
-- 1.
SELECT username, phone, address
FROM Customer
WHERE address LIKE '%서울%';
-- 2.
SELECT username, phone
FROM Customer
WHERE custid IN (SELECT custid FROM Orders);
SELECT username, phone
FROM Customer
WHERE address LIKE '%서울%'
UNION
SELECT username, phone
FROM Customer
WHERE custid IN (SELECT custid FROM Orders);
-- 도서 주문에서 주소가 대한민국이 있는 고객의 이름, 전화번호를 출력하자.
-- 단, 전화번호가 없는 경우 '전화없음' 표시를 하자.
SELECT username, IFNULL(phone, '전화없음')
FROM Customer
WHERE address LIKE '대한민국%'
UNION
SELECT username, IFNULL(phone, '전화없음')
FROM Customer
WHERE custid IN (SELECT custid FROM Orders);
/* IN */
-- 주문 테이블에 25000 이상 주문한 고객의 이름, 주소와 책 제목을 출력하시오.
SELECT C.custid, C.username, C.address, B.bookname
FROM Customer C, Book B
WHERE C.custid IN (SELECT custid
FROM Orders WHERE saleprice > 2000);
/* 02. 다중행 연산자 */
-- "예" 주문 테이블에서 40000 이상 주문한 고객의 이름, 주소와 책 제목을 조회.
SELECT C.username, C.address, B.bookname
FROM Customer C, Book B
WHERE c.custid IN (SELECT custid
FROM Orders
WHERE saleprice > 40000);
/* EXIST */
-- "예" 주문이 있는 고객의 이름, 주소 정보를 출력하자.
-- 1
SELECT *
FROM Orders O, Customer C
WHERE C.custid = O.custid;
-- f
SELECT username, address
FROM Customer C
WHERE EXISTS (SELECT *
FROM Orders O
WHERE C.custid = O.custid);
/* ALL */
-- 주문일자가 2021-02-05 이전 주문 금액보다 비싼 모든 도서를 출력하시오.
SELECT bookid FROM orders
WHERE orderdate < '2021-02-05';
-- all
SELECT bookname, publisher, price FROM BOOK
WHERE price > ALL (SELECT bookid FROM orders
WHERE orderdate < '2021-02-05');
/* ANY */
-- 메인쿼리
SELECT bookname, price FROM book;
-- "예" 주문 테이블에서 주문가격이 5000 에서 20000 사이 도서의 도서 이름, 도서 가격을 조회하자.
-- 1
SELECT saleprice
FROM ORDERS
WHERE saleprice between 5000 and 20000;
-- f
SELECT bookname, price
FROM BOOK
WHERE price = ANY (SELECT saleprice
FROM ORDERS
WHERE saleprice between 5000 and 20000);[141차시]View 이해하고 사용하기
뷰(view)
- 하나 이상의 테이블을 결합하여 만든 가상의 테이블
- SELECT와 조건 구문 등을 통해서 쿼리로서 가상의 테이블로 생성한다
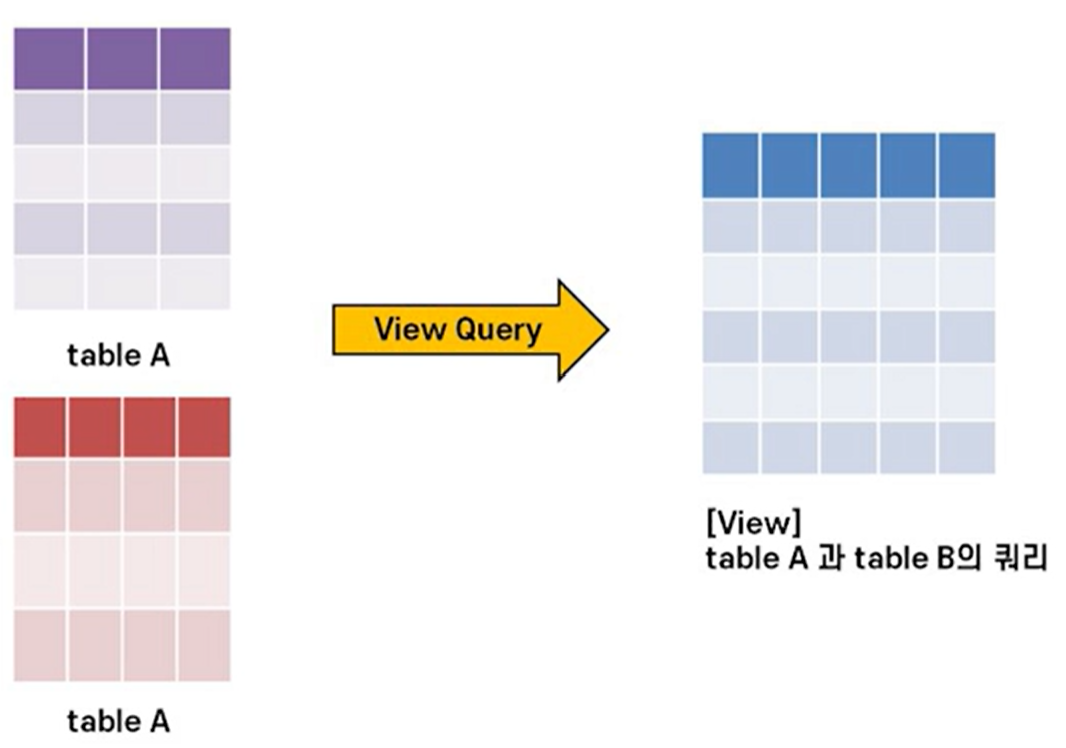
뷰의 특징
- 원본 테이블의 레코드 값에 따라 뷰의 레코드도 같이 변화가 일어남
- 기존 테이블 변경없이 새로운 데이터 구조를 사용할 수 있음
- 특정 레코드에 대한 노출이 필요한 경우 장점이 있음
뷰의 단점
- 뷰에 독립적인 인덱스 생성이 어려움
- 한 번 생성된 뷰의 속성 변경이 안됨
- ALTER VIEW문을 사용할 수 없다. (뷰의 정의를 변경할 수 없다.) - 삽입, 삭제, 갱신, 연산에 많은 제약이 따름
- 테이블의 기본키를 포함한 속성의 뷰에서 삽입, 삭제, 갱신, 연산이 가능하다.
뷰의 장점
- 편리성 및 재사용성
- 자주 사용되는 복잡한 질의를 뷰로 미리 정의해 놓을 수 있다.
- 반복적이고 복잡한 질의를 간단히 뷰로 작성해 일반 쿼리로 사용한다.
- 사용자가 요구에 맞게 가공하여 뷰로 사용할 수 있다.
- 보안
- 사용자별로 필요한 데이터만 선별하여 보여줄 수 있다.
- 민감 정보 질의의 경우 뷰로 내용을 암호화해서 제공할 수 있다.
- 논리적 독립성
- 미리 정의된 뷰를 일반 테이블처럼 사용할 수 있다.
- 원본 테이블의 구조가 변해도 응용에 영향을 주지 않도록 하는 논리적 독립성을 제공한다.
CREATE VIEW 구문

※ SELECT 구문: Join, Subquery 및 제약사항을 포함한 쿼리
CREATE OR REPLACE VIEW 구문

※ CREATE 구문으로 view_name에 따라서 새로운 뷰로 생성된다.
DROP VIEW 구문

→ 뷰를 삭제한다.
[142차시]실습: View 생성과 갱신
/* View 이해하고 사용하기 */
CREATE VIEW v_orders
AS SELECT orderid, O.custid, username, O.bookid, saleprice, orderdate
FROM Customer C, Orders O, Book B
WHERE C.custid = O.custid and B.bookid = O.bookid;
SELECT * FROM V_ORDERS;
-- 도서 가격이 20000이상인 레코드로 변경
CREATE OR REPLACE VIEW v_orders(custid, username, address)
AS SELECT C.custid, username, address
FROM Customer C, Orders O, Book B
WHERE B.price > 20000;
SELECT * FROM V_ORDERS;
-- 고객 구매 뷰
CREATE OR REPLACE VIEW V_CUST_PURCHASE
AS
SELECT C.USERNAME AS 고객, SUM(O.SALEPRICE) 구매액
FROM CUSTOMER C, ORDERS O
WHERE C.CUSTID = O.CUSTID
GROUP BY 고객
ORDER BY 구매액 DESC
;
SELECT * FROM V_CUST_PURCHASE;
-- 구매 고객의 매출 순위
SELECT 고객,
RANK() OVER(ORDER BY 구매액 DESC) AS '매출순위'
FROM V_CUST_PURCHASE
;
-- 뷰 삭제
DROP VIEW V_ORDERS;
DROP VIEW V_CUST_PURCHASE;[143차시]다양한 집계 함수 결합
집계함수

수치형 집계함수

기간 집계함수

- mode 값

View와 집계함수
: 반복적, 지속적, 주기적 쿼리를 View로 생성해서 단순한 SELECT 만으로 집계 결과를 얻고자 함
[144차시]실습: 뷰를 통한 집계
/* 숫자 집계함수 */
SELECT GREATEST(29, -100, 34, 8, 25);
SELECT GREATEST("windows.com", "microsoft.com", "apple.com");
SELECT CEILING(30.75);
SELECT CEILING(40.25);
SELECT CEILING(40);
SELECT ROUND(30.75, 1);
SELECT ROUND(100.925, 2);
-- 평균도서가격
SELECT CEILING(SUM(PRICE)/COUNT(PRICE)) 평균
, SUM(PRICE)/COUNT(PRICE) 평균2
FROM BOOK;
/* 날짜 집계함수 */
-- WEEKOFYEAR(), YEARWEEK()
SELECT WEEKOFYEAR('2021-01-01'); -- 2020년의 53주에 해당.
SELECT WEEK('2021-01-01', 3);
SELECT WEEKOFYEAR('2021-01-05'); -- 2021년의 1주에 해당.
SELECT WEEKOFYEAR('2021-02-01'); -- 2021년의 5주에 해당.
SELECT WEEKOFYEAR('2021-12-31'); -- 2021년의 52주에 해당.
--
SELECT YEARWEEK('2021-01-01'); -- 2020년의 52주에 해당.
SELECT YEARWEEK('2021-01-03', 2);
SELECT YEARWEEK('2021-01-05');
SELECT YEARWEEK('2021-08-02', 7);
SELECT DAYOFYEAR("2021-01-01");
SELECT DAYOFYEAR("2021-06-15");
SELECT DAYOFYEAR("2021-12-31");
-- 주문한 년도별 가격과 평균가격
SELECT YEAR(ORDERDATE) 년도,
SUM(SALEPRICE) 합계,
CEILING(SUM(SALEPRICE)/COUNT(SALEPRICE)) 평균
FROM ORDERS
GROUP BY YEAR(ORDERDATE);
SELECT YEAR(ORDERDATE) 년도,
SUM(SALEPRICE) 합계,
CEILING(SUM(SALEPRICE)/COUNT(SALEPRICE)) 평균
FROM ORDERS
GROUP BY 1;
/* view와 집계 함수 */
-- 주별 최소/최대 판매가 집계
SELECT YEARWEEK(orderdate)
, orderdate
, MIN(saleprice)
, MAX(saleprice)
FROM Orders
GROUP BY YEARWEEK(orderdate);
CREATE OR REPLACE VIEW v_Weekly(Weekly, Date, MIN, MAX)
AS SELECT YEARWEEK(orderdate) Weekly, orderdate 'Date',
MIN(saleprice) MIN, MAX(saleprice) MAX
FROM Orders
GROUP BY YEARWEEK(orderdate);
SELECT * FROM v_Weekly;
-- 특정 기간에 대한 요일별 판매량
-- 요일별 판매량 보고서는 특정 기간동안 Sun에서 Sat 요일별 판매량를 리포팅 해줍니다
-- 1. 수량 처리
SELECT count(orderid) AS 수량 FROM ORDERS;
SELECT count(custid) AS 수량 FROM ORDERS;
-- 2. 요일별 수량 처리
SELECT
CASE DAYOFWEEK(orderdate)
WHEN 1 THEN "Sun"
WHEN 2 THEN "Mon"
WHEN 3 THEN "Tue"
WHEN 4 THEN "Wed"
WHEN 5 THEN "Thu"
WHEN 6 THEN "Fri"
WHEN 7 THEN "Sat"
END AS 요일,
count(orderid) AS 수량
FROM Orders;
-- 3. 기간별 통계
SELECT
CASE DAYOFWEEK(orderdate)
WHEN 1 THEN "Sun"
WHEN 2 THEN "Mon"
WHEN 3 THEN "Tue"
WHEN 4 THEN "Wed"
WHEN 5 THEN "Thu"
WHEN 6 THEN "Fri"
WHEN 7 THEN "Sat"
END AS 요일
,count(custid) AS 수량
FROM Orders
WHERE date_format(orderdate,"%Y-%m-%d") BETWEEN "2021-01-01" AND "2021-08-31"
GROUP BY DAYOFWEEK(orderdate);
-- 5. 뷰 생성
CREATE OR REPLACE VIEW v_weekday(요일, 수량)
AS
SELECT
CASE DAYOFWEEK(orderdate)
WHEN 1 THEN "Sun"
WHEN 2 THEN "Mon"
WHEN 3 THEN "Tue"
WHEN 4 THEN "Wed"
WHEN 5 THEN "Thu"
WHEN 6 THEN "Fri"
WHEN 7 THEN "Sat"
END AS 요일
,count(custid) AS 수량
FROM Orders
WHERE date_format(orderdate,"%Y-%m-%d") BETWEEN "2021-01-01" AND "2021-08-31"
GROUP BY DAYOFWEEK(orderdate)
;
SELECT * FROM V_WEEKDAY;👥 파트너간 상보적 학습 및 강의 내용 리뷰

강의를 듣던 도중 WHERE문에 집계함수를 사용할 수 없다는 이야기가 나왔는데 원리가 잘 이해되지 않았다.
팀별 이야기 시간에 팀원분들께 여쭤보니 집계함수는 SELECT나 HAVING절에 사용해야 한다고 했다.
그 이유로는 SQL문의 논리 순서가 원인인것 같다고 했했다.
4.11 SELECT SQL의 논리적인 처리 순서
본 글은 MySQL과 실제 주식 데이터로 SQL을 공부할 수 있는 책, '평생 필요한 데이터 분석'의 내용입니다. 4.11 SELECT SQL의 논리적인 처리 순서 SELECT SQL 작성 시 실수하지 않도록 논리적인 처리
sweetquant.tistory.com
참고할 수 있는 싸이트도 알려주셔서 SQL의 논리 처리 순서도 함께 학습했다.
🙋♀️ 질문&답변
오늘은 코드 오류가 많았다.
강사님이 강의에서 실행하실 때는 잘 돌아가는데 내 컴퓨터에서 실행하면 자꾸 에러가 났다.
강사님 컴퓨터는 마법 컴퓨터🧙♂️
[오류 코드]
-- 고객이 주문한 도서의 총 판매액, 평균값, 최저가, 최고가를 구하고,
-- 판매된 도서의 종류를 개수로 조회하자
SELECT SUM(saleprice) AS 총매출,
AVG(saleprice) AS 평균,
MIN(saleprice) AS 최소값,
MAX(saleprice) AS 최대값,
C.USERNAME AS 고객,
COUNT(DISTINCT B.BOOKID) AS 도서수
FROM Orders O, BOOK B, CUSTOMER C
WHERE O.BOOKID = B.BOOKID
AND C.CUSTID = O.CUSTID
;
💡조원들과 찾은 문제점: USERNAME으로 GROUP BY를 해주지 않아서 오류가 발생한 것이다.
💁♂️ A. USERNAME으로 GROUP BY를 하거나 해당 줄을 삭제한다
-- 구매 고객이 가격 8000 이상 도서의 주문 수량을 구하는데 단 2권 이상 주문한
-- 고객이름, 수량, 판금액을 조회하자.
select C.USERNAME AS 이름,
COUNT(*) AS 수량,
SUM(O.saleprice) AS 판매액
FROM Orders O, BOOK B, CUSTOMER C
WHERE O.bookid = B.bookid
and O.custid = C.custid
and O.saleprice >= 8000
GROUP BY O.custid
HAVING count(*) >= 2;
💡조원들과 찾은 문제점: 조인이 이루어지지 않았다.
💁♂️ A. 조인하기
C.USERNAME이 나오는 이유: pk로 그룹핑이 되어서 (사실 이것도 잘 이해못함)
🤷♀️ Q. WHERE절에서 집계함수를 사용할 수 없는 이유가 궁금합니다.위 코드의 WHERE절을 WHERE price < AVG(price) 로 바꾸었을때도 같은 맥락으로 오류가 발생하는 것일까요?
💁♂️ A. where절은 데이터를 가져오는 기능이 없으므로, 집계함수를 사용할 수 없고, 서브쿼리를 사용해야 합니다.
암튼 그냥 안되는거!!!
📌 workbench에서 ERD보는법: Database > Reverse Engineer > reverse 할 테이블 선택


마지막 예제에서 다룬 문제에 왜 테이블명을 바꾸니 결과가 제대로 출력이 되는지 이해가 안가서 우리 엔젤 조원들에게 물어봤다👼 custid에서 해당 조건을 조회하면 "한번이라도" 25000원 이상 도서를 구매한 고객의 id가 모두 뽑혀서 나오고, orderid에 조회하면 25000원 이상 도서를 구매한 주문번호로 조회가 되는것! 명확한 설명에 이해가 척척👍
✍️ 추가 공부
SQL 작성 순서: SELECT - FROM - WHERE - GROUP BY - HAVING - ORDER BY - LIMIT
마무리하며
SQL과 함께한 폭풍같은 하루.. 어렵고 헷갈리는 개념이 많았다😵💫
실습 코드 오류 때문에 번거롭긴 했지만,, 오류를 해결해해가는 과정에서 알아가는게 많았다. 코드 오류 오히려 좋아~
내일이면 벌써 SQL이 끝난다! R도 처음이라 걱정되지만 열심히 하면 괜찮겠지~라는 마음으로 내일도 화이팅!

* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 2주차 학습 일지 (1) | 2023.02.17 |
|---|---|
| [👩💻TIL 10일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.17 |
| [👩💻TIL 8일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.15 |
| [👩💻TIL 7일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.14 |
| [👩💻TIL 6일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.13 |



