
홍동이의 성장일기
[👩💻TIL 10일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
[155차시]다른 데이터와 그룹화, 순위, 랭킹 다루기
[기초부터 익히는 R]
[145차시]기본통계 이해하기
기본통계
기술통계
- 대표값
: COUNT, MAX/MIN/MEDIAN, SUM/AVERAGE, RANK 함수 - 주기적 통계
- 중심경향성
- 대표값 파악: 산술평균, 기하평균, 중앙값
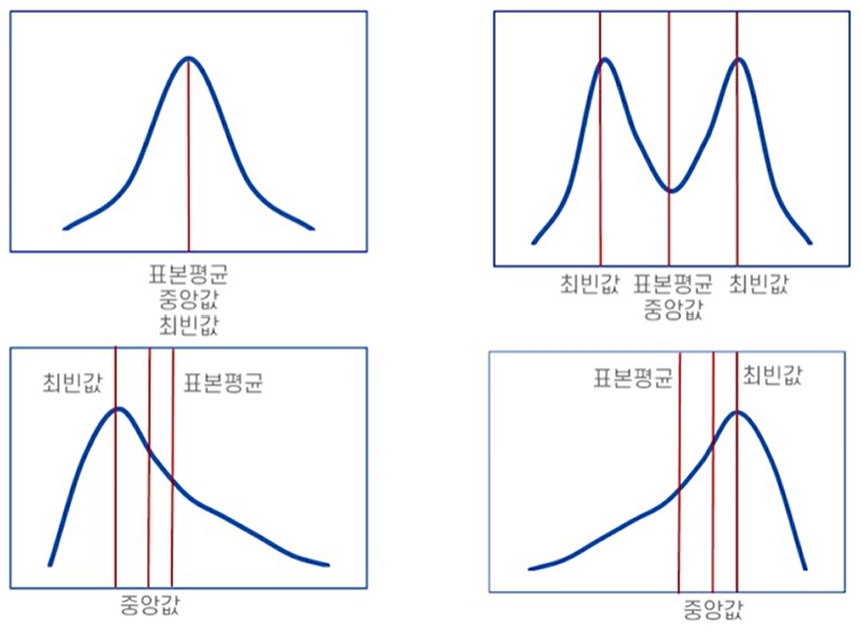

- 데이터의 분포
- 분산, 표준편차, 사분위수

[146차시]실습: 기술적 통계 사용해 보기
-- 고객의 전체 주문횟수, 합계, 평균, 최소/최대 구매액을 조회하자.
SELECT C.USERNAME 이름,
COUNT(*) 주문량,
FORMAT(SUM(SALEPRICE),0) 합계,
FORMAT(AVG(SALEPRICE), 1) 평균,
MAX(SALEPRICE) 최대,
MIN(SALEPRICE) 최소
FROM ORDERS O
LEFT JOIN CUSTOMER C
ON O.CUSTID = C.CUSTID
GROUP BY 이름;
-- 년도별 주문량, 주문 합계, 평균, 최대 및 최소 값을 계산하자.
SELECT YEAR(ORDERDATE) 년도,
COUNT(*) 주문량,
FORMAT(SUM(SALEPRICE),0) 합계,
FORMAT(AVG(SALEPRICE), 1) 평균,
MAX(SALEPRICE) 최대,
MIN(SALEPRICE) 최소
FROM ORDERS O
LEFT JOIN CUSTOMER C
ON O.CUSTID = C.CUSTID
GROUP BY 1;
-- 주문 금액의 합계, 평균, 최소, 최대, 분산, 표준편차
SELECT SUM(SALEPRICE) 합계,
FORMAT(AVG(SALEPRICE), 1) 평균,
MAX(SALEPRICE) 최대,
MIN(SALEPRICE) 최소,
FORMAT(VARIANCE(SALEPRICE),1) 분산,
FORMAT(STD(SALEPRICE),1) 표준편차
FROM ORDERS;
/* 사분위수
- GROUP_CONCAT 함수로 데이터를 합쳐서 분위수에 해당하는 수치를 구해 SUBSTRING_INDEX함수로 데이터를 추출하는 방법이다.
- 합쳐지는 데이터가 많을 경우 꼭 SET GROUP_CONCAT_MAX_LEN = 10485760; 와 같은 설정이 필요함
*/
/* 가격 개수를 이용한 사분위수 */
-- 1단계:
-- group_concat(name [separator][order by]) : 컬럼 결과를 한 줄로 결합
SELECT publisher, GROUP_CONCAT(bookname SEPARATOR ':')
FROM book
GROUP BY publisher;
-- 2단계:
-- 모든 가격을 결합한다.
SELECT GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ',')
FROM Orders;
-- 3단계: 전체 레코드 수를 25%~100% 까지 계산해 본다.
SELECT 25/100 * COUNT(saleprice) + 1 AS '25%',
50/100 * COUNT(saleprice) + 1 AS '50%',
70/100 * COUNT(saleprice) + 1 AS '75%',
MAX(saleprice) AS 'MAX'
FROM Orders;
-- 4단계:
-- substring_index(str, delim, count)
-- 문자열 str 을 delim 로 구분해서 배열로 만든 후 count 만큼만 보여준다.
-- count 가 양수이면 왼쪽에서 count 수만큼 보여주고 음수이면 오른쪽에서 count 수 만큼 보여준다.
select substring_index('www.mysql.com', '.', 1); -- 'www'
select substring_index('www.mysql.com', '.', -1); -- 'com'
-- 5단계: FINAL
-- 합쳐지는 데이터가 많을 경우 꼭 SET GROUP_CONCAT_MAX_LEN = 10485760; 와 같은 설정이 필요함
-- SET GROUP_CONCAT_MAX_LEN = 10485760;
SELECT MIN(saleprice) AS 'MIN',
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 25/100 * COUNT(*) + 1), ',', -1) AS `25%`,
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 50/100 * COUNT(*) + 1), ',', -1) AS `50%`,
AVG(saleprice) AS 'MEAN',
SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(saleprice ORDER BY saleprice SEPARATOR ','),',', 75/100 * COUNT(*) + 1), ',', -1) AS `75%`,
MAX(saleprice) AS 'MAX'
FROM Orders;
/* 전체 가격 범위는 판매가를 합산 가격으로 계산해 사분위 범위 */
SELECT MIN(saleprice) AS 'MIN',
FORMAT(25/100 * SUM(saleprice), 1) AS '25%',
FORMAT(50/100 * SUM(saleprice), 1) AS '50%',
FORMAT(AVG(saleprice),1 ) AS 'MEAN',
FORMAT(70/100 * SUM(saleprice), 1) AS '75%',
MAX(saleprice) AS 'MAX'
FROM Orders;[147차시]순위, 소계, 피벗 등 사용하기
순위
※ V8부터 지원


그루핑해서 순위를 매기고자 할 때 PARTITION BY 사용
-- 고객별 주문가격 랭킹
select o.custid, o.bookid, b.bookname, o.saleprice,
rank() over (partition by o.custid order by o.saleprice desc) ranking
from orders o, book b
where o.bookid = b.bookid;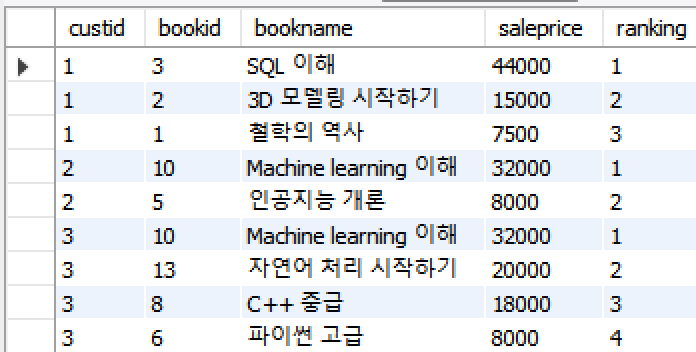
소계
그룹 함수로 집계된 데이터에서 소계, 합계는 ROLLUP을 사용하면 됨

select substring_index(address, ' ', 1) 지역,
ifnull(b.bookname, '---소계---') 도서명,
count(*) 판매수량
from customer c, orders o, book b
where c.custid = o.custid
and b.bookid = o.bookid
group by 지역, b.bookname with rollup;
[148차시]실습: 다양한 순위 집계하기
/* 순위 */
-- 대여비용의 랭킹
-- 도서 주문 가격별 랭킹
SELECT B.bookname
, RANK() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
-- 도서 주문 가격별 랭킹: DENSE_RANK
SELECT B.bookname, DENSE_RANK() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
-- 도서 주문 가격별 랭킹: ROW_NUMBER
SELECT B.bookname, ROW_NUMBER() OVER (ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
-- 주문 가격별 고객의 랭킹
SELECT B.bookname,
O.CUSTID,
ROW_NUMBER () OVER (PARTITION BY O.CUSTID ORDER BY O.SALEPRICE) AS RANKING
FROM BOOK B, ORDERS O
WHERE B.BOOKID=O.BOOKID
GROUP BY 1;
/*
* 롤업 : 소계
*/
/* MYSQL 안됨.
-- 방법1 : GROUP BY ROLLUP(그룹컬럼)
SELECT BOOKID, CUSTID, SUM(SALEPRICE) AS 판매액
FROM ORDERS
WHERE BOOKID IN (2,3,4)
GROUP BY ROLLUP(BOOKID, ORDERDATE); */
-- "예" 지역별로 판매된 도서의 수량을 조회하자.
-- 방법1 : GROUP BY 그룹컬럼 WITH ROLLUP
-- 지역중심으로 집계
SELECT SUBSTRING(address, 1, 12) as 지역,
bookname,
COUNT(*) 수량
FROM Customer C, Book B, Orders O
WHERE O.bookid = B.bookid AND C.custid = O.custid
GROUP BY address WITH ROLLUP
ORDER BY username ASC, bookname DESC;
-- 밥업2 : Having IS NOT NULL 로
SELECT SUBSTRING(address, 1, 12) as 지역,
bookname,
COUNT(*) 수량
FROM Customer C, Book B, Orders O
WHERE O.bookid = B.bookid AND C.custid = O.custid
GROUP BY address WITH ROLLUP
HAVING address IS NOT NULL
ORDER BY username ASC, bookname DESC;
-- GROUP BY 구문에 제시된 컬럼에 따라 결과는 달라질 수 있다.
SELECT SUBSTRING(address, 1, 12) as 지역,
Bookname,
COUNT(*) 수량
FROM Customer C, Book B, Orders O
WHERE O.bookid = B.bookid AND C.custid = O.custid
GROUP BY address, bookname WITH ROLLUP
HAVING address IS NOT NULL
ORDER BY username ASC, bookname DESC;
[149차시]샘플 데이터베이스 구성
샘플 데이터베이스 준비
Sakila 데이터베이스
: MySQL 설치시 포함된 샘플 데이터베이스
MySQL :: Sakila Sample Database
This document describes Sakila sample database installation, structure, usage, and history. For legal information, see the Legal Notices. For help with using MySQL, please visit the MySQL Forums, where you can discuss your issues with other MySQL users. Do
dev.mysql.com
기본 Sample 데이터베이스 Salkia 없는 경우 다운로드한 Dump_Salkia.sql을 Import한다.
Database > Reverse Engineer > Salkia
[150차시]SQL활용 영화,배우,스태프 테이블 탐색
/* 배우, 나라 테이블 */
DESC ACTOR;
SELECT COUNT(*) FROM ACTOR;
SELECT COUNT(*) FROM FILM;
SELECT COUNT(*) FROM CUSTOMER;
SELECT COUNT(*) FROM STAFF;
SELECT COUNT(*) FROM RENTAL;
SELECT COUNT(*) FROM INVENTORY;
-- 배우 이름
SELECT UPPER(CONCAT(FIRST_NAME, ' ', LAST_NAME)) '배우'
FROM ACTOR;
-- SON으로 끝나는 성을 가진 배우
SELECT *
FROM ACTOR
WHERE UPPER(LAST_NAME) LIKE '%SON';
-- 배우들이 출연한 영화
SELECT
UPPER(CONCAT(FIRST_NAME, ' ', LAST_NAME)) '배우',
F.TITLE,
F.RELEASE_YEAR
FROM FILM F, ACTOR A, FILM_ACTOR B
WHERE A.ACTOR_ID = B.ACTOR_ID
AND B.FILM_ID = F.FILM_ID;
-- 성 별 배우 숫자
SELECT LAST_NAME, COUNT(*) AS 명
FROM ACTOR
GROUP BY LAST_NAME
ORDER BY 명 DESC , LAST_NAME;
DESC COUNTRY;
--
SELECT COUNTRY_ID, COUNTRY
FROM COUNTRY
WHERE COUNTRY IN ('AUSTRALIA', 'GERMANY');
[151차시]그룹화, 순위, 랭킹 다루기
/* staff table*/
SELECT CONCAT(STF.FIRST_NAME, ' ', STF.LAST_NAME) STAFF,
ADR.ADDRESS, ADR.DISTRICT, ADR.POSTAL_CODE, ADR.CITY_ID
FROM STAFF STF LEFT JOIN ADDRESS ADR
ON STF.ADDRESS_ID = ADR.ADDRESS_ID;
-- 임금
-- 1
SELECT CONCAT(STF.FIRST_NAME, ' ', STF.LAST_NAME) STAFF
FROM STAFF;
SELECT SUM(PAY.AMOUNT) PAY
FROM PAYMENT PAY;
SELECT
CONCAT(STF.FIRST_NAME, ' ', STF.LAST_NAME) STAFF,
SUM(PAY.AMOUNT) PAY
FROM STAFF STF LEFT JOIN PAYMENT PAY
ON STF.STAFF_ID = PAY.STAFF_ID
WHERE MONTH(PAY.PAYMENT_DATE) = 7
AND YEAR(PAY.PAYMENT_DATE) = 2005
GROUP BY STF.FIRST_NAME , STF.LAST_NAME;
-- 영화별 출연 배우의 수
SELECT FLM.TITLE, COUNT(*) 배우
FROM FILM FLM INNER JOIN FILM_ACTOR FIM_ACT
ON FLM.FILM_ID = FIM_ACT.FILM_ID
GROUP BY FLM.TITLE
ORDER BY 배우 DESC;[152차시]집계 테이블 활용 탐색
/* 영화, 등급 테이블 */
-- 서브쿼리
-- 영화 'HALLOWEEN NUTS'에 출연한 배우들
SELECT CONCAT(FIRST_NAME, ' ', LAST_NAME) 배우
FROM ACTOR
WHERE ACTOR_ID IN (SELECT ACTOR_ID
FROM FILM_ACTOR
WHERE FILM_ID IN (SELECT FILM_ID
FROM FILM
WHERE LOWER(TITLE) = LOWER('HALLOWEEN NUTS')));
-- 국가가 CANADA인 고객의 이름
-- 1. SUBQUERY
SELECT CONCAT(FIRST_NAME, ' ', LAST_NAME) 고객, EMAIL
FROM CUSTOMER
WHERE ADDRESS_ID IN (SELECT ADDRESS_ID
FROM ADDRESS
WHERE CITY_ID IN (SELECT CITY_ID
FROM CITY
WHERE COUNTRY_ID IN (SELECT COUNTRY_ID
FROM COUNTRY
WHERE COUNTRY = 'CANADA')));
-- 국가가 CANADA인 고객의 이름
-- 2. JOIN
SELECT CONCAT(CUS.FIRST_NAME, ' ', CUS.LAST_NAME) 고객, CUS.EMAIL
FROM CUSTOMER CUS JOIN ADDRESS ADR
ON CUS.ADDRESS_ID = ADR.ADDRESS_ID
JOIN CITY CIT
ON ADR.CITY_ID = CIT.CITY_ID
JOIN COUNTRY COU
ON CIT.COUNTRY_ID = COU.COUNTRY_ID
WHERE COU.COUNTRY = 'CANADA';
-- 영화 등급
SELECT RATING, COUNT(*)
FROM film
GROUP BY RATING;
-- 영화에서 pg 또는 G 등급
SELECT RATING, COUNT(*) 수량
FROM FILM
WHERE RATING = 'PG' OR RATING = 'G'
GROUP BY RATING;
-- 영화에서 pg 또는 G 등급 영화 제목
SELECT RATING, TITLE, RELEASE_YEAR
FROM FILM
WHERE RATING = 'PG' OR RATING = 'G'
GROUP BY RATING;
-- 대여비 관련
-- 대여비가 1 ~ 6 이하
SELECT DISTINCT RENTAL_RATE
FROM FILM;
SELECT TITLE, RATING
FROM FILM
WHERE RENTAL_RATE BETWEEN 1.0 AND 6.0;
-- 등급별 영화의 수를 출력
SELECT RATING, COUNT(*)
FROM FILM
GROUP BY RATING;
--
-- 대여비가 1 ~ 6 이하인 등급별 영화의 수를 출력
SELECT RATING, COUNT(*)
FROM FILM
WHERE RENTAL_RATE BETWEEN 1.0 AND 6.0;
-- 등급별 영화 수와 합계, 최고, 최소 비용
SELECT RATING, COUNT(*) 수량,
SUM(RENTAL_RATE) 합계,
AVG(RENTAL_RATE) 평균,
MIN(RENTAL_RATE) 최소,
MAX(RENTAL_RATE) 최고
FROM FILM
GROUP BY RATING, RENTAL_RATE;
-- 등급별 영화 수와 합계, 최고, 최소 비용을 조회하고 평균 렌탈 비용으로 정렬
SELECT RATING, COUNT(*) 수량,
SUM(RENTAL_RATE) 합계,
AVG(RENTAL_RATE) 평균대여비,
MIN(RENTAL_RATE) 최소,
MAX(RENTAL_RATE) 최고
FROM FILM
GROUP BY RATING, RENTAL_RATE
ORDER BY AVG(RENTAL_RATE) DESC;
-- 등급별 영화 개수, 등급, 평균렌탈 비용을 출력하고 평균 렌탈비용을 내림차순으로 해서 하자
SELECT RATING, COUNT(*) AS 수량, AVG(RENTAL_RATE) AS 평균대여비
FROM FILM
GROUP BY RATING
ORDER BY 평균대여비 DESC;[153차시]공공데이터를 선택과 스키마 구성
공공자전거 대여이력 정보
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
현재 패킷 크기 출력
select @@max_allowed_packet/1024/1024;

대용량 데이터 덤프 시 my.ini
my.ini위치: 작업관리자 > 서비스 > MySQL80 속성 (관리자 권한) > max_allowed_packet 크기를 200M로 수정 > 서비스 재시작 > 패킷 크기 조회
공공데이터 스키마 준비
강의 자료에 올라와있는 덤프를 사용했다.
SQL 덤프 import
Server > Data Import에서 덤프가 있는 파일을 지정해준 후 Start Import를 누르면 스키마가 설치된다.
[154차시]데이터 종류, 지표 등 살펴보기
SQLite
새 데이터베이스 만들기
파일 > 가져오기 > CSV 파일에서 테이블 가져오기 > 첫 행에 필드명 포함 > 인코딩: EUC-KR
덤프파일로 내보내기
파일 > 내보내기 > 데이터베이스를 SQL로 내보내기 > 옵션 전체 선택 > 데이터만 내보내기
[155차시]다른 데이터와 그룹화, 순위, 랭킹 다루기
use seoul_data;
/* 1. 테이블 생성 */
-- 2020/12월 공공자전거 테이블
CREATE TABLE IF NOT EXISTS `bicycle_202012` (
`자전거번호` varchar(12),
`대여일시` datetime,
`대여소번호` int,
`대여소명` varchar(100),
`대여거치대` int DEFAULT NULL,
`반납일시` datetime,
`반납대여소번호` int,
`반납대여소명` varchar(100),
`반납거치대` int DEFAULT NULL,
`이용시간` int DEFAULT NULL,
`이용거리` double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
/*
CREATE TABLE `bicycle_rent` (
`ID` varchar(12), -- 자전거번호
`LD_TIME` datetime, -- 대여일시
`ST_ID` int, -- 대여소번호
`ST_NAME` varchar(100), -- 대여소명
`LD_RACK` int DEFAULT NULL, -- 대여거치대
`RT_TIME` datetime, -- 반납일시
`RT_STID` int, -- 반납대여소번호
`RT_ST` varchar(100), -- 반납대여소이름
`RT_RACK` int DEFAULT NULL, -- 반납거치대
`U_TIME` int DEFAULT NULL, -- 이용시간
`U_DIST` double DEFAULT NULL -- 이용거리
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
*/
/* 2. 데이터 들여오기 */
SELECT @@max_allowed_packet / 1024 / 1024;
/*
SELECT @@max_allowed_packet / 1024 / 1024;
SET GLOBAL max_allowed_packet=10000000000;
SELECT @@max_allowed_packet / 1024 / 1024;
SELECT @@innodb_flush_log_at_trx_commit;
*/
-- show variables like 'local_infile';
-- SET GLOBAL local_infile = 1;
-- LOAD DATA LOCAL INFILE 'D:/Db_공공데이터-SQLite3/공공자전거 대여이력 정보_2020.12.csv' INTO TABLE bicycle_rent FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\r\n' IGNORE 1 LINES;
/* 3. bicycle_202012 데이터 살펴보기 */
select count(*) from bicycle_202012;
desc bicycle202012;
--
SELECT count(*) from bicycle202012;
-- 대여소 숫자
select count(distinct `대여소번호`), count(distinct `대여소명`) from bicycle202012;
-- 자전거 숫자
select count(`자전거번호`), count(distinct `자전거번호`) from bicycle202012;
-- 대여소별 자전거 숫자
select `대여소명`, count(`자전거번호`) 자전거숫자
from bicycle202012
group by `대여소명`
order by 2 desc;
select `대여소명`,count(distinct `자전거번호`) 회전
from bicycle202012
group by `대여소명`
order by 2 desc;
-- 자전거별
select `자전거번호`, count(`이용시간`) 횟수, sum(`이용시간`) 시간
from bicycle202012
group by `자전거번호`
order by 3 desc;
USE seoul_data;
/* 시간날짜 형식으로 업데이트
SELECT 대여일시 FROM bicycle_rental;
-- UPDATE bicycle_rental SET
-- 대여일시 = STR_TO_DATE(대여일시, '%Y-%m-%d %H:%i:%s');
SELECT STR_TO_DATE(대여일시, '%Y-%m-%d %H:%i:%s') D
FROM bicycle_rental
WHERE DATE_FORMAT(STR_TO_DATE(대여일시, '%Y-%m-%d %H:%i:%s'), "%Y-%m-%d") = "2021-12-01";
SELECT DATE_FORMAT(STR_TO_DATE(대여일시, '%Y-%m-%d %H:%i:%s'), "%Y-%m-%d") FROM bicycle_rental;
*/
-- 기본 테이블
DESC BICYCLE_202012;
-- BICYCLE_RENTAL 뷰 생성
CREATE OR REPLACE VIEW BICYCLE_RENTAL
AS SELECT * FROM BICYCLE_202012;
DESC BICYCLE_RENTAL;
--
SELECT * FROM BICYCLE_RENTAL limit 10;
-- 대여소 숫자
-- 2095 1185907
SELECT COUNT(DISTINCT 대여소번호 ) 대여소숫자, COUNT(*) 레코드수
FROM BICYCLE_RENTAL;
-- 자전거 수량
SELECT COUNT(DISTINCT 자전거번호) 수량
FROM BICYCLE_RENTAL;
-- 대여소별 사용한 자전거 수량
SELECT 대여소번호, 대여소명, COUNT(DISTINCT 자전거번호) 수량
FROM BICYCLE_RENTAL
GROUP BY 대여소번호
ORDER BY 3 DESC;
-- 대여소별 사용한 자전거
SELECT 대여소번호, COUNT(자전거번호) 수량
FROM BICYCLE_RENTAL
GROUP BY 대여소번호;
-- 대여소별 이용량이 많은 곳.
SELECT 대여소번호, 대여소명, SUM(이용시간)
FROM BICYCLE_RENTAL
GROUP BY 1,2
ORDER BY 3 DESC ;
-- 월별 이용시간 집계
SELECT DATE_FORMAT(대여일시,'%Y-%m') MONTHLY,
SUM(이용시간) 합계,
AVG(이용시간) 평균,
MIN(이용시간) 최소,
MAX(이용시간) 최대,
AVG(이용거리) 평균거리
FROM BICYCLE_RENTAL
GROUP BY MONTHLY
ORDER BY 1;
-- 자전거별 월별 이용시간 집계
SELECT 자전거번호,
DATE_FORMAT(대여일시,'%Y-%m') 월간,
SUM(이용시간) 합계,
AVG(이용시간) 평균,
MIN(이용시간) 최소,
MAX(이용시간) 최대,
AVG(이용거리) 평균거리
FROM BICYCLE_RENTAL
GROUP BY 자전거번호, 월간
ORDER BY 1;
/* 대여횟수 */
-- 월별 대여횟수
SELECT DATE_FORMAT(대여일시,'%Y-%m') 월간, OUNT(대여일시) 횟수
FROM BICYCLE_RENTAL
GROUP BY 1
ORDER BY 1;
-- 월 기준 대여소별 대여횟수
SELECT DATE_FORMAT(대여일시,'%Y-%m') MONTHLY, 대여소명, COUNT(대여일시) 횟수
FROM BICYCLE_RENTAL
GROUP BY MONTHLY, 대여소명
ORDER BY 1;
-- 월 기준 대여소의 자전거별 대여횟수
SELECT DATE_FORMAT(대여일시,'%Y-%m') 월간
, 대여소명
, 자전거번호
, COUNT(대여일시) 횟수
FROM BICYCLE_RENTAL
GROUP BY 월간, 대여소명, 자전거번호
ORDER BY 4 DESC;
-- 월 기준 대여소의 자전거별 대여횟수
SELECT DATE_FORMAT(대여일시,'%Y-%m') 월간
, 대여소명
, 자전거번호
, COUNT(대여일시) 횟수
, SUM(이용시간) 총시간
FROM BICYCLE_RENTAL
GROUP BY 월간, 대여소명, 자전거번호
ORDER BY 4 DESC;
-- 일별 이용량
SELECT DATE_FORMAT( 대여일시, "%Y%m%d") AS 대여일시,
COUNT(*) 수량,
AVG(이용시간) 평균시간,
AVG(이용거리) 평균거리
FROM BICYCLE_RENTAL
GROUP BY 대여일시
ORDER BY 1 ASC;
-- 일별+대여소 이용량
SELECT DATE_FORMAT( 대여일시, "%Y%m%d") AS 대여일시,
대여소명,
COUNT(자전거번호) 수량,
AVG(이용시간) 평균시간,
AVG(이용거리) 평균거리
FROM BICYCLE_RENTAL
GROUP BY 대여일시, 대여소명
ORDER BY 1 ASC;
SELECT 대여소번호
, 대여소명
, COUNT(DISTINCT 자전거번호) 수량
FROM BICYCLE_RENTAL
GROUP BY 대여소번호
ORDER BY 3 DESC;
-- 총이용시간별 대여소 등급
SELECT 대여소번호
, 대여소명
, COUNT(DISTINCT 자전거번호) 수량
, SUM(이용시간) AS 총시간
, CASE
WHEN (SUM(이용시간) >= 80000) THEN '최우수'
WHEN (SUM(이용시간) >= 15000) THEN '우수'
WHEN (SUM(이용시간) >= 8000 ) THEN '일반'
ELSE '기타'
END AS '등급'
FROM BICYCLE_RENTAL
GROUP BY 대여소명
ORDER BY 4 DESC;[156차시]데이터의 Top 50, Top 10 집계
use seoul_data;
--
/* 1. '202101' 파일을
- DBBrowser for SQLite에서 SQL 덤프 생성
*/
/* 2. 테이블 */
CREATE TABLE IF NOT EXISTS `bicycle_202101` (
`자전거번호` varchar(12),
`대여일시` datetime,
`대여소번호` int,
`대여소명` varchar(100),
`대여거치대` int DEFAULT NULL,
`반납일시` datetime,
`반납대여소번호` int,
`반납대여소명` varchar(100),
`반납거치대` int DEFAULT NULL,
`이용시간` int DEFAULT NULL,
`이용거리` double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
/* 2. 데이터 들여오기 */
SELECT @@max_allowed_packet / 1024 / 1024;
/* 3. bicycle_202101 데이터 살펴보기 */
select count(*) from bicycle_202012;
select count(*) from bicycle_202101;
desc bicycle_202101;
/* 3. View 생성 */
-- BICYCLE_RENTAL 뷰 생성
CREATE OR REPLACE VIEW BICYCLE_RENTAL
AS
SELECT * FROM BICYCLE_202012
UNION
ALL
SELECT * FROM BICYCLE_202101
;
DESC BICYCLE_RENTAL;
/* - 데이터 Top 50, Top 10 집계
*/
-- 대여소 숫자
-- 기존 202012 테이블: 2095 1185907
SELECT COUNT(DISTINCT 대여소번호 ) 대여소숫자, COUNT(*) 레코드수
FROM BICYCLE_RENTAL;
-- 자전거 수량
SELECT COUNT(DISTINCT 자전거번호) 수량
FROM BICYCLE_RENTAL;
-- 대여소별 이용량이 많은 곳.
SELECT 대여소번호, 대여소명, COUNT(*)
FROM BICYCLE_RENTAL
GROUP BY 1,2
ORDER BY 3 DESC ;
-- 대여소별 이용시간이 평균보다 높은 곳.
SELECT 대여소번호, 대여소명, COUNT(*) 횟수
FROM BICYCLE_RENTAL
WHERE 이용시간 >= ( SELECT AVG(이용시간) FROM BICYCLE_RENTAL)
GROUP BY 1,2
ORDER BY 3 DESC ;
-- 2. 요일별 평균 이용시간
SELECT
CASE DAYOFWEEK(대여일시)
WHEN 1 THEN "Sun"
WHEN 2 THEN "Mon"
WHEN 3 THEN "Tue"
WHEN 4 THEN "Wed"
WHEN 5 THEN "Thu"
WHEN 6 THEN "Fri"
WHEN 7 THEN "Sat"
END AS 요일
, AVG(이용시간) AS 시간
FROM BICYCLE_RENTAL
WHERE 이용시간 >= ( SELECT AVG(이용시간) FROM BICYCLE_RENTAL)
GROUP BY 1;
SELECT DATE_FORMAT(대여일시,'%Y-%m') MONTHLY
, CASE DATE_FORMAT( 대여일시, '%p')
WHEN 'AM' THEN "오전"
WHEN 'PM' THEN "오후"
END AMPM
, AVG(이용시간) AS 시간
FROM BICYCLE_RENTAL
WHERE 이용시간 >= ( SELECT AVG(이용시간) FROM BICYCLE_RENTAL)
GROUP BY 1;
/* 소계 이용 */
-- ifnull 활용
SELECT IFNULL(대여소명,'소계')
, IFNULL(자전거번호,'소계')
, SUM(이용시간)
FROM BICYCLE_RENTAL
WHERE DATE_FORMAT(대여일시,'%Y-%m-%d') BETWEEN "2020-12-01" AND "2020-12-05"
GROUP BY 대여소명, 자전거번호 WITH ROLLUP;
-- v8 이후 GROUPING 지원
SELECT IF(GROUPING(대여소명),'소계',대여소명)
, IF(GROUPING(자전거번호),'소계',자전거번호)
, SUM(이용시간)
FROM BICYCLE_RENTAL
WHERE DATE_FORMAT(대여일시,'%Y-%m-%d') BETWEEN "2020-12-01" AND "2020-12-05"
GROUP BY 대여소명, 자전거번호 WITH ROLLUP;
/* 이용량 Top10 */
-- 대여소별 이용량이 많은 곳에 대한 top10
-- 1 대여소별 순위
SELECT 대여소번호
, 대여소명
, COUNT(*) 수량
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM BICYCLE_RENTAL
GROUP BY 1,2;
-- 2 대여소별 순위에서 TOP10
SELECT *
FROM (
SELECT 대여소번호
, 대여소명
, COUNT(*) 수량
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM BICYCLE_RENTAL
GROUP BY 1,2
) A
WHERE RNK <= 10;
-- 월 기준 대여소별 이용량이 많은 곳에 대한 top10
SELECT DATE_FORMAT(대여일시,'%Y-%m') MONTHLY
, 대여소명
, COUNT(*) 횟수
, ROW_NUMBER() OVER(ORDER BY COUNT(*) DESC) RNK
FROM BICYCLE_RENTAL
GROUP BY MONTHLY, 대여소명;
[157차시]R이 무엇인가요?
R이란?
: 전산 통계학(computational Statistics)을 위한 프로그래밍 언어

- 화상처리(Graphics): 시각화
- C, Fortran으로 작성된 함수형 프로그래밍 언어
빅데이터
빅데이터의 특징: 3V
- Volumne: 양
- Variety: 다양성
- 정형 데이터 (표, excel)
- 준정형 데이터 (XML, JSON)
- 비정형 데이터 (사진, 비디오, 오디오, 위치 정보, 생체 기록 정보, 검색 로그)
- Velocity: 속도
- 빠른 생성 & 처리 (분석, 시각화)
| 5V | 7V | ||
| Veracity: 진실성 | 데이터를 신뢰할 수 있는가? | Validity: 정확성 | 데이터의 품질이 좋은가? |
| Value: 가치 | 가치를 창출할 수 있는 데이터인가? | Volatility: 휘발성 | 오랜 기간 활용될 수 있는 데이터인가? |
[158차시]R의 장단점
유사 분석 프로그램
- 표 형태의 분석 프로그램: Excel
| 장점 | 단점 |
| 메뉴 기반 - 프로그래밍 지식 필요 X - 손쉽게 사용가능 |
고급 통계, 전문적인 시각화 작업 어려움 |
| 다양한 매크로 함수 제공 | 다양한 기능 한꺼번에 적용 힘듦 |
| 다양한 셀 단위 시각화 가능 ex. 조건부서식, 그래프, 원차트 |
반복 작업에 비효율 |
| 익숙한 MS Office 문서 기반 |
- 범용 프로그래밍 언어: Python
| 장점 | 단점 |
| 매우 뛰어난 확장성 - 응용 프로그램 개발 - 웹/앱 개발 - 인공지능 연구 |
디버깅 난이도 높음 |
| 강력한 IDE: Jupyter notebook | 특정 데이터 형식 시각화 기능 미흡 ex. Network graph |
| 무료 |
- 공학용 프로그램 패키지: Mat(rix) lab
| 장점 | 단점 |
| 수식 계산에 탁월 | 유료 |
| 간편성 - 방대한 매크로 함수 |
통계분석 기능 미흡 |
| 시각화 성능 우수 |
- SQL: 데이터 베이스 관리 프로그램
- Tableau: 데이터 스토리텔링 특화
- Power BI: Microsoft Office 기반 툴
- Google Analytics: 웹 로그 데이터 분석 툴 (ex. 사이트 방문자 통계, 방문 경로 분석 등)
R의 장점
[언어적 측면]
- 통계 계산용 패키지 매우 우수
: dplyr, tidyr, stringr, lubridate - 강력한 시각화 패키지 제공
: ggplot2, rgl, htmlwidgets - 뛰어난 확장성
- 초기에는 확장성 좋지 않았으나, 다양한 패키지 등장
- 웹기반 분석결과 리포팅
: ggvis, shiny - 인공지능 연구
: Ime4/nlme, randomForest, caret, deepnet
[사용자 측면]
- 유저 커뮤니티 활성화
- 대부분의 유저들이 유사한 목표를 가짐
- 디버깅 용이
- 상대적으로 학습난이도 낮음
- 다양한 OS 지원
: Windows, Mac, Linux - 무료
R의 단점
- 느린 속도
: 범용 프로그래밍 언어보다 처리 속도 느림 - 한정된 사용성
: 대규모 IT 서비스 개발에 접목이 어려움 (ex. 게임개발에 부적합) - 보안 기능 없음
R vs Python
| 공통점 | 차이점 |
| 무료 - Open source - 다양한 패키지 지속적 업데이트 중 |
통계분석 + 시각화 vs 범용 |
| 활발한 커뮤니티 | [Python 우세] 확장성 |
| 우수한 IDE | [R 우세] 통계분석, 시각화 디버깅 데이터 처리까지 필요한 공부량 |
→ 상황과 목적에 알맞은 데이터 분석 프로그램 선택 능력 증진 필요
[159차시]R의 범용성
R활용 가능 분야
데이터 마이닝
: Data + mining = 데이터로부터 정보를 채굴
- 목적: 데이터 모집단의 패턴을 찾아 새로운 데이터를 예측, 군집화, 분류
텍스트 마이닝
- 웹 등에서 방대한 텍스트 정보 크롤링
- 단어 빈도순으로 가중치 주어 시각화
소셜 네트워크 분석
- 사람 간 관계 시각화: SNS 팔로우, 친구추가 데이터 사용
지도 분석
주식 분석
: 증권사 등에서 제공하는 API 사용하여 데이터 수집
이미지 분석
- 이미지 라벨링
- 이미지 구획 나누기
사운드 분석
- 아날로그 소리 데이터를 디지털 벡터 데이터로 변환
- SST(Speech To Text) & TTS
- 음성 품질 향상
웹 애플리케이션 개발
- R 언어만을 사용하여 웹에서 데이터 분석 내용 시각화 가능
: 데모 시연용으로 주로 사용됨 - 논문, 발표 슬라이드 등 제작 가능
코드
##################################################
# 고객별 총 주문횟수, 총구매액, 평균구매액, 최소/최대구매액 구하기
# 구매하지 않은 고객 포함하기
# 구매하지 않은 고객은 집계 결과 0으로 표현하기
# 총 구매액 순으로 순위 매기기(RANK)
##################################################
SELECT C.username AS 이름,
COUNT(O.orderid) AS 구매횟수,
IFNULL(SUM(saleprice),0) AS 총구매액,
IFNULL(avg(saleprice),0) AS 평균구매액,
IFNULL(min(saleprice),0) AS 최소값,
IFNULL(max(saleprice),0) AS 최대값,
rank() over (order by sum(saleprice) DESC) AS 순위
FROM Customer C
LEFT JOIN Orders O ON C.custid = O.custid
GROUP BY C.custid;
##################################################
# 고객별 saleprice 랭킹
##################################################
select c.username, b.bookname, o.saleprice
,RANK() OVER(partition by c.username ORDER BY o.saleprice desc) 순위
from orders o, customer c, book b
where o.custid=c.custid and o.bookid=b.bookid;
##################################################
# 지역-도서별 판매 수량
# 지역별 판매수량 소계
##################################################
select substring_index(address,' ',1) as 지역,
b.bookname as 도서명,
count(*) 총판매수량 ,
sum(o.saleprice) 총판매금액
from customer c, orders o, book b
where c.custid = o.custid
and o.bookid = b.bookid
group by 1,2 with rollup;
마무리하며
R에 대해 궁금했었는데 R에 대한 다양한 지식을 접할 수 있어서 흥미로운 시간이었다. 그리고 SQL 코드가 너무 이해가 안간다😵💫 주말동안 추가 학습을 해야할 것 같다.
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 11일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.20 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 2주차 학습 일지 (1) | 2023.02.17 |
| [👩💻TIL 9일차 ] 유데미 스타터스 취업 부트캠프 4기 (2) | 2023.02.16 |
| [👩💻TIL 8일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.15 |
| [👩💻TIL 7일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.14 |



