
홍동이의 성장일기
[👩💻TIL 12일차 ] 유데미 스타터스 취업 부트캠프 4기 본문

목차
[173차시]R 연산자와 함수
연산자란?
- 연산: 프로그램에서 데이터를 처리하여 결과를 산출하는 과정
- 연산자: 연산을 수행하기 위해 사용되는 문자
- 피연산자
- 연산을 당하는 대상
- R에서는 객체에 해당

산술 연산자
: 프로그램이 산술적인 연산을하도록 하는 연산자
- 산술 연산자 종류

비교 연산자
: 두 데이터 사이의 크기 비교를 수행하는 연산자
→ 결과는 논리형으로 리턴됨
- 비교 연산자 종류

논리 연산자
: 값 또는 자료구조 객체에 적용되는 논리기능 수행하는 연산자
→ 결과는 논리형으로 리턴됨
- 논리 연산자 종류

산술 함수
Min 함수: 입력 벡터 중 최소값 출력
Max 함수: 입력 벡터 중 최대값 출력
Sum 함수: 입력 벡터 중 총합 출력
Prod 함수: 입력 벡터 중 곱셈 값 출력
Factorial 함수: 1부터 입력값까지의 팩토리얼 값 출력
Abs 함수: 입력 벡터 중 총합 출력
prod(c(1, 2, 3, 4, 5)) #120
factorial( 4 ) #4! = 24
factorial( c(1 2 -3 4) ) # 1 2 NaN 24
abs(-3) # 3
abs( c(1, -2, 3, -4, 5)) #1 2 3 4 5Mean 함수: 입력 벡터의 평균 값 출력
Median 함수: 입력 벡터의 중간 값 출력
Range 함수: 입력 벡터의 최소값 최대값 출력
range( c(1, 2, 3, 4, 5)) #1 5
range( c(10, 2, 4, 4, 77)) #2 77Var 함수: 입력 벡터의 평균에 대한 분산값 출력
Sd 함수: 입력 벡터의 평균에 대한 표준편차값 출력
문자열 관련 함수
Paste 함수: 값들을 하나의 문자열로 합치는 함수
Rep 함수 rep(data, n): data로 초기화되는 길이가 n인 벡터 생성
paste(‘안녕’, ‘하세’, ‘요’) # ‘안녕 하세 요’
paste(‘안녕’, ‘하세’, ‘요’, sep=“”) # ‘안녕하세요’
paste(‘안녕’, ‘하세’, ‘요’, sep=“/”) # ‘안녕/하세/요’
paste(c(1, 2, 3)) # c(‘1', ‘2', ‘3') , 벡터 값들을 개별로 인식
paste(c(1,2,3), c(‘번’, ‘번’, ‘번’)) # c(‘1 번‘, ‘2 번’, ‘3 번’)
rep(1, 5) # c(1, 1, 1, 1, 1)
rep(‘a’, 5) # c(‘a’, ‘a’, ‘a’, ‘a’, ‘a’)
index <- c(1,2,3)
len <- length(index) # index 벡터의 크기 리턴
paste( index, rep(‘번’, len) ) # c(‘1 번‘, ‘2 번’, ‘3 번’)
실습

# Q.1 운항/탑승객/화물 별 ‘총 실적’ 및 ‘평균 실적‘을 구하세요.
#데이터 입력
airline <- c('아시아나항공', '에어부산', '에어프레미아', '에어서울', '제주항공', '진에어', '대한항공', '티웨이항공')
flight <- c(1575, 481, 124, 354, 1197, 793, 1670, 859)
passenger <- c(249792, 90985, 29238, 71213, 203335, 133253, 250895, 146497)
freight <- c(3097.9, 516.7, 111.1, 273.1, 847.1, 763.2, 5406.1, 597.6)
#계산 및 출력
total <- c(sum(flight), sum(passenger), sum(freight))
average <- total / length(flight) # length(): 입력된 매개변수의 크기 리턴
print(total)
print(average)
#Q.2 운항이 평균 실적보다 높은 항공사들을 벡터 형태로 출력하세요.
#계산 및 출력
upperAvg_flight <- flight > mean(flight) #평균 운항 실적과 항공사별 운항실적 비교
print(upperAvg_flight) # c(TRUE, FALSE, FALSE, FALSE, TRUE, FALSE, TRUE, FALSE)
result <- airline[upperAvg_flight] # airline 벡터 중 TRUE에 해당하는 index 값만 남김
print(result) # c(‘아시아나항공’, ‘제주항공’, ‘대한항공’)
[174차시]조건문
조건문이란?
- 지정한 조건에 해당할 때, 코드를 수행하는 구문
- 조건문 안에 들어가는 값은 반드시 논리값임

if ~ else문
- 문법

- 다중 조건식 사용 가능: Else if 구문 사용

※ scan(): 사용자로부터 데이터 입력 받는 함수. 값 입력없이 엔터 누를 시, 입력 종료
ifelse문 (삼항연산자)
- 문법

- 특징
- 벡터 연산 가능
- 간단한 조건문에 한하여 가독성 목적으로 사용
- 실행문이 복잡한 경우에 적합하지 않음
- 다중 조건식에 부적합
switch문
- 문법
- 입력값과 비교값이 같다면 해당하는 실행문 실행
if(입력값 == 비교값){실행문} - 기본 실행문은 입력값과 같은 비교값이 없을 때 실행
- 입력값과 비교값이 같다면 해당하는 실행문 실행

- 특징
- 비교값은 문자열 형식만 가능
- 범주형 데이터 처리해야하는 경우 효율적
which문
- 문법
- 조건에 해당하는 입력 벡터 내부 값의 인덱스(위치) 출력

- 특징
- 조건에 따른 실행문 실행 기능 없음
[175차시]반복문
반복문이란?
- 프로그램 내에서 똑같은 명령을 일정 횟수만큼 반복하여 수행하도록 제어하는 명령문
- 조건문과 더불어 가장 많이 사용되는 제어문
- 대부분 조건문과 함께 사용됨

For문
- 문법
- 데이터에 존재하는 값이 순서대로 변수에 할당되어 명령문 실행
- 데이터의 마지막 값까지 반복

While문
- 문법
- 조건식이 FALSE라면 반복 종료
- 산술값 계산 or 위치(index)값을 사용할 때 주로 사용

※ break: 반복문 안에서 사용시 강제로 반복 종료
Repeat문
- 문법
- 가장 간단한 반복문 구조
- 잘 사용하지 않음

벡터 다루기
- 위치(index)값 사용하여 벡터 내부값 참조/할당 가능
- 위치값은 1부터 시작
- 문법: 벡터명[위치값]

- 특징
- 다중위치 참조 가능
- logic 벡터 값이 TRUE인 index 값만 리턴
- num 벡터 값에 해당하는 index 값만 리턴 - 음수 위치값 사용 가능
: 해당 자릿수 값만 빼고 리턴
- 다중위치 참조 가능
[176차시]사용자 정의 함수
사용자 정의 함수
: 사용자가 직접 정의하여 만들어내는 함수
- 문법
- 매개변수1: 초기화가 되지 않았기 때문에 필수 매개변수
- 매개변수2: 초기화되었기 때문에 선택적 매개변수

- 벡터에 index별 이름 설정 가능
- c(이름1=값, 이름2=값, ...)
- 이름에 적힌 값은 문자열로 자동 형변환되어 취급
※ Sys.Date(): 시스템 상 오늘의 날짜를 리턴하는 함수. "yyyy-mm-dd" 형
※ difftime: Date간 차이에 해당하는 일수 리턴
- 특징
- 매개변수, 함수 내부변수 우선순위: 함수 내부변수 우선
- 함수 안에서 사용한 변수 밖에서 사용 불가능
- 함수 안 함수 선언 가능
단, 동일한 매개변수명 사용 불가 - 함수를 리턴 가능
: 함수를 생산하는 함수
파일에 함수 저장하기
- 별도 파일에 함수 저장
- 일반적으로 사용자 정의 함수 사용하는 방법
- 패키지와 유사
- 함수 외 변수, 데이터셋 저장가능
- 파일 저장 방법
- 새 r스크립트 생성
- 함수 작성
- r스크립트 working directory에 저장: getwd()
- 파일 불러오기
- 새로운 r스크립트 생성
- source 함수 사용하여 파일 불러오기: source()
- 파일 내부에 저장된 함수 사용
[177차시]데이터 가져오기와 내보내기
데이터 형식
"컴퓨터가 사용할 수 있는 데이터는 어떤 형식으로 존재할까?"
- 키보드 입력
- 키보드로 사용자에게 데이터를 직접 입력 받음
- scan()
- 로컬 파일
- 로컬 컴퓨터에 저장된 파일
- 인터넷 연결 유무 상관없이 사용
- 인터넷 파일
- 인터넷에 업로드 되어있는 파일
- 다운로드 필요
데이터 가져오기
키보드 입력
- scan()
: numeric 형식 값만 입력 가능 - scan(what = character())
: character 형식 값 입력 가능 (logical도 가능)
로컬 파일
: 데이터 파일에 자주 사용되는 확장자
- .txt
- 데이터들을 구분자로 분리하여 저장
- 구분자가 여러 개거나, 없는 경우도 존재
- .csv (Comma Separated Values)
- 구분자가 콤마(,)인 데이터 파일
- .xlsx
- 엑셀 파일
- 웹 관련 확장자: xml, json, html 등
read.table: 테이블(행렬) 형식 파일로부터 데이터 불러오는 함수
- 문법
- header: 데이터 첫 행에 열 변수명이 있다면 TRUE(default), 없다면 FALSE
- sep: 구분자 지정가능
- col.names
- 열 변수명 임의 설정가능
- header가 True라면 굳이 할 필요없음 - na.string: 결측치를 의미하는 문자가 어떤 것인지 지정

read.csv: csv 형식 파일로부터 데이터 불러오는 함수
- 문법
- read.table과 구조는 같지만 csv는 sep가 콤마(,)로 고정되어있기 때문에 sep에 대한 매개변수가 없다.

read.excel: xlsl, xls 형식 엑셀 파일로부터 데이터 불러오는 readxl 패키지 함수
→ readxl 패키지 인스톨 및 로드 필요
#패캐지 설치 및 로딩
install.packages("readxl")
library(readxl)- 문법
- sheet
- sheet가 여러 개인 경우, sheet명 지정
- 지정하지 않으면 첫번째 sheet 데이터 불러옴 - range: 데이터 불러올 범위 지정 가능
- cell_rows: 행 모두 리턴
- R0C0:R0C0 (R: Rows, C: Columns) - col_names: read.table의 header와 기능 동일
- col_types: read.table의 col.names와 기능 동일
- na: read.table의 na.string와 기능 동일
- sheet

인터넷 파일
: 인터넷에 존재하는 데이터 파일 로딩
- 데이터 주소(url)를 기존 파일 로딩함수 매개변수에 삽입
- read.table, read.csv 함수는 url 통한 로딩 제공
- readxl 패키지의 read_xlsx는 url 통한 로딩 제공하지 않음
데이터 내보내기
write.table
- 문법
- row.name: 행 번호 붙힐지 말지 선택
- quote: character 형식 데이터에 쌍따옴표(") 붙힐지 말지 선택

write.csv
: sep에 대한 매개변수가 없다는 것 외에는 write.table과 동일함

write.excel
: "writexl" 패키지 설치 필요
- 문법

[178차시]데이터 확인, 조작
데이터 확인
기본 확인 함수
- 데이터셋 선정
- dim 함수: 데이터의 차원 확인
- length 함수: 데이터가 가진 마지막 차원의 수를 보여줌
※ 데이터 프레임에서 '$' 표시를 사용하여 특정 열 컬럼만 추출할 수 있다 - head 함수: 앞쪽 6개 데이터만 출력
- tail 함수: 쪽 6개 데이터만 출력
- str 함수
- class, 크기, 미리보기 값 제공
- factor: 범주형 데이터임을 의미하는 문자열 벡터
- names 함수: 데이터의 헤더 이름 출력
- View 함수: RStudio 뷰어 창에서 데이터 확인
※ V는 반드시 대문자로 써야함
행/열 추출
- 데이터 특정 행/열만 추출 (행, 열)
- data.frame[c(1,2), ] : 데이터 프레임의 '1,2행/ 모든 열' 만 추출
- data.frame[, c(1,2)] : 데이터 프레임의 ‘모든 행/ 1,2 열’ 만 추출
- data.frame[c(1,2), c(1,2)] : 데이터 프레임의 ‘1,2 행/ 1,2 열' 만 추출
- 데이터 특정 행/열만 제거
- data.frame[c(-1,-2), ] : 데이터 프레임의 1,2행 제거
- data.frame[, c(-2)] : 데이터 프레임의 2열 제거
- data.frame[c(-1,-2), c(-1,-2)] : 데이터 프레임의 ‘1,2 행/ 1,2 열’ 제거
데이터 분석
기본 분석
- mean, var, sd (평균, 분산, 표준편차)
- table 함수
- 벡터 내에서 데이터 값이 각각 몇 회 등장하였는지 체크
- 범주형 데이터 분석에 적합
- median, range(min, max)
- quantile (사분위수)
[179차시]데이터 그리기
데이터 그리기
plot() 함수: 산점도, 그래프 그리기
- 문법
- x, y: 데이터의 x, y축 값
- type: 그래프 타입 (p: 점, l: 선, b: 점&선 등)
- main: 그래프 제목
- x/ylab: x/y축 이름
- x/ylim: x/y축 값 범위
- pch: 점의 모양 (숫자 1~25, 문자: "*", "%", "#" 등)

다중 그래프 그리기
- 방법
- plot() 함수 사용하여 1개 그래프 그린 후, lines() 함수 사용하여 추가 그래프 그림
- plot을 통해 그림을 그리고 lines를 통해 plot 위에 추가로 그림을 덧칠하는 개념
※ col: 그래프 선 색 지정 매개변수
범례 그리기
- 그래프의 라벨을 알려주는 값
legend(위치값, legend = 라벨값, fill = 색상값)- 위치값 (9가지): topright/left, top, bottom, bottomleft/right, center, left, right
파이 차트
pie() 함수 (원형 차트): 비율을 표현하여 범주형 데이터 시각화에 적합

- label: 요소별 이름 등록
- init.angel: 기준선 각도
- radius: 원의 크기 조절
※ table 객체 삽입 시, label이 자체적으로 붙음
히스토그램
hist() 함수: 수치형 데이터를 범주화하여 표현하는데 적합
- 문법
- breaks: 범주 개수
- frep: 결과 출력값 기준 (T = 횟수(count), F = 비율(density))

상자그림
boxplot() 함수: 수치형 데이터의 분포를 시각화하는데 적합
- 상자그림이란?
- 5가지 통계수치를 표현: 최대값, 1/2/3사분위값, 최소값
- 이상치표현: 최대값보다 매우 크거나, 최소값보다 매우 작은값

- 문법
- boxwex: 상자의 넓이

※ 다중상자그림: data.frame 형식 데이터 사용할 시, 컬럼별 boxplot 그려짐
[180차시]데이터 조작 기본 실습
#데이터 로딩
#C열에 항공명, L열에 화물 실적 데이터 존재
data <- read_excel("airport.xlsx", col_names = FALSE, range="R80C3:R85C12") # 80행 C열부터 85행 L열까지의 데이터 로딩
head(data)
#데이터에서 '항공사별 화물 실적'데이터를 추출
airportName <- data$...1 # 항공명
freight <- as.numeric(data$...10) # 화물 실적
# 추출한 데이터를 파이차트로 그림. (단, 항공사명, 비율 라벨 추가해야 함)
freight_percent<- freight / sum(freight) * 100
freight_percent <- round(freight_percent, digit=1) #round: 반올림 함수, 소숫점 1째자리에서 반올림
label_data <- paste(airportName, "(", freight_percent,"%", ")")
label_data
pie(freight, label=label_data, radius=1)
#데이터로딩
data <- read.csv("covid19.csv", header=F, skip=35, nrows=30) #header는 없으며, 앞의 35줄을 skip하고 그 다음부터 30줄을 로딩
dim(data)
data <- data[30:1,] #데이터 위아래 뒤집기(reverse)
#9월 한달간 '당일 1차 접종자', '당일 2차 접종자‘ 데이터를 추출
#9월 한달간 '1차 접종률', '2차 접종률' 데이터를 추출
first_vaccine <- data$V3 #일일 1차 접종자 데이터 추출
second_vaccine <- data$V6 #일일 1차 접종자 데이터 추출
first_rate <- data$V5 # 1차 접종률 데이터 추출
second_rate <- data$V8 # 1차 접종률 데이터 추출
#화면분할 출력
par(mfrow = c(2,1))
plot(first_vaccine, type='o', col='red', pch=19, xlab="day", ylab="count", main="코로나 일일 백신 접종 수")
lines(second_vaccine, type='o', col='blue', pch=19)
legend("bottomright", legend=c('first', 'second'), fill=c("red", "blue"))
plot(first_rate, type='o', col='red', pch=19, xlab="day", ylab="rate(%)", ylim=c(20,80), main="총 백신 접종률 (%)")
lines(second_rate, type='o', col='blue', pch=19)
legend("bottomright", legend=c('first', 'second'), fill=c("red", "blue"))
#Q3
data <- read.csv('TravelMode.csv')
head(data)
dim(data) # (840 10)
choice <- data$choice
choice_yes_index <- which(choice == "yes")
choice_yes_index
actual_data <- data[choice_yes_index,] #choice값이 yes인 행과, 그 행들의 모든 열로 이루어진 데이터 프레임
head(actual_data)
processed_data <- actual_data[,c(-1, -2, -4)] # x, individual, choice 칼럼 제거
head(processed_data)
str(processed_data) # 생성한 데이터셋 확인
#boxplot
boxplot_data <- processed_data[,c(-1, -4, -7)] #mode, travel, size 컬럼 제외
boxplot(boxplot_data)
#히스토그램
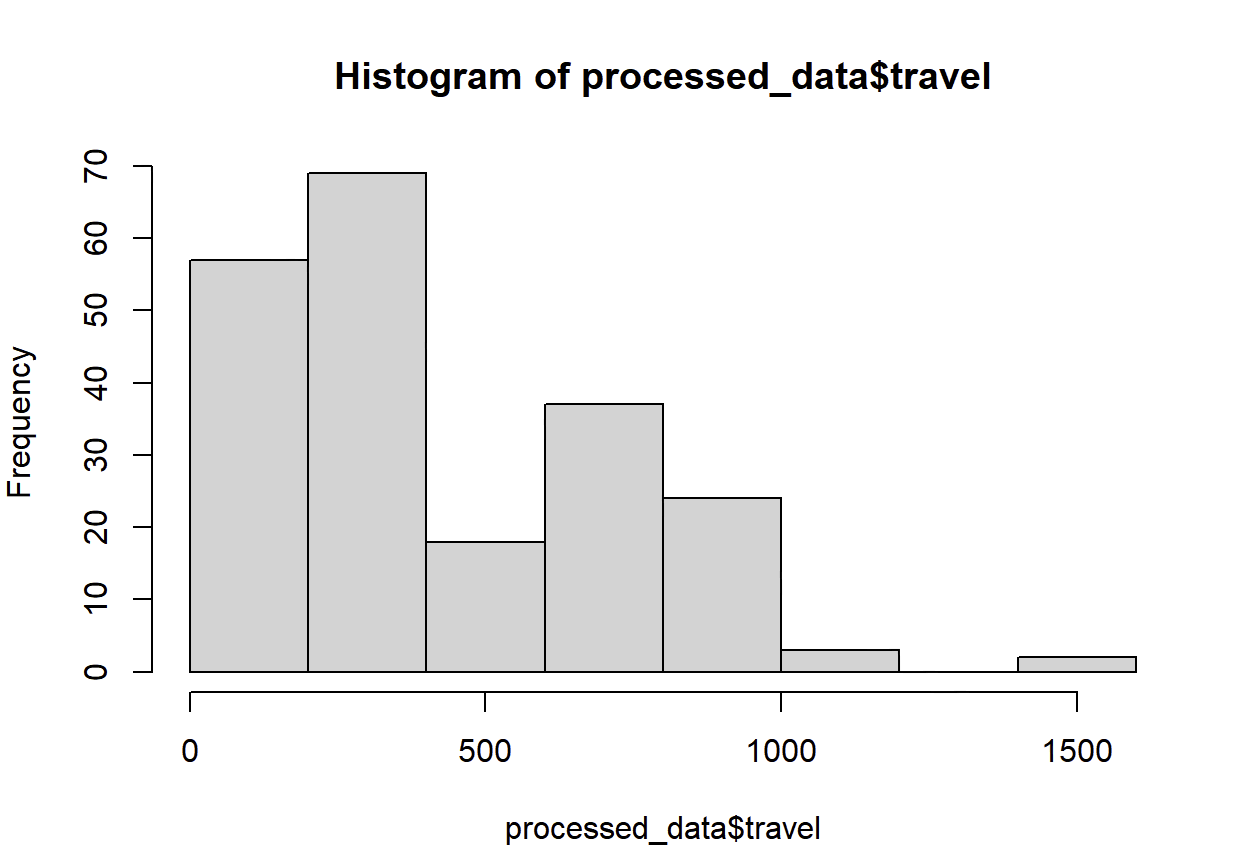
hist(processed_data$travel)
[181차시]dplyr패키지 설치와 파이프 연산자
dplyr 패키지 소개
왜 중요한가요?
- 현실의 데이터는 더럽다
- 전처리에 많은 시간 사용 + 힘듦
→ 비교적 단순한 반복 작업이 많기 때문 - 전처리를 쉽게해주는 R 패키지
- 데이터 전처리 시, 반복작업을 줄여줌
- 처리속도 빠름
- C++ 기반
- 이전 버전인 plyr은 R 기반 패키지 → 느림
- 파이프 연산자 제공
- 가독성
- 메모리 효율성
설치

파이프 연산자 (체인 연산자)

- 문법
- 형태: %>%
- 의미: 왼쪽 변수를 오른쪽 함수에 적용
- f(x) 구조를 x %>% f 구조로 사용
- 왼쪽 변수는 오른쪽 함수의 첫번째 파라미터로 적용 - dplyr 패키지에서 제공하는 연산자
- 값 조작을 위해 사용하는 함수가 많을수록 가독성 측면에서 장점
- 전처리 과정이 복잡할수록 코드 작성 및 이해가 편함
- 단축키: Ctrl + Shift + M
dplyr 함수 소개
rename 함수
: 데이터프레임에서 특정 컬럼의 이름 변경
- 문법

arrange 함수
: 데이터프레임에서 특정 컬럼 값을 기준으로 데이터 정렬
- 문법

distinct 함수
: 데이터프레임에서 특정 컬럼의 중복값제거
- 문법

[182차시]dplyr 주요 함수 이해
dplyr 주요 함수 소개
select 함수
: 데이터 프레임에서 원하는 컬럼만 추출
- 문법

filter 함수
: 데이터 프레임에서 조건에 충족되는 행만 추출
- 문법
- & (and), | (or)을 사용하여 여러 행 추출 가능

mutate 함수
: 기존 컬럼값을 사용하여 새로운 컬럼을 생성
- 문법

group_by 함수
: 특정 컬럼 값이 같은 데이터들을 같은 집단으로 묶어줌
- 문법

- 특징
- group_by만으로는 외관상 달라지는게 없음
- grouped_df 형식으로 변경됨: group 관련 정보 추가
summarize 함수
: 그룹 단위 동일기능 수행 후, 새로운 데이터 프레임에 수행 결과 통합
- 문법
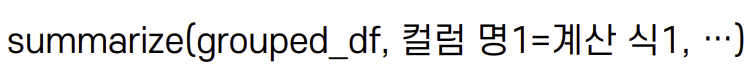
[183차시]테이블 조작 실습
데이터셋 소개: gapminder
: 국가별 경제 수준과 의료 수준 동향을 정리한 데이터셋
- 경제적 수준: 일인당 GDP
- 의료 수준: 평균 기대수명
※ pull(): tibble 자료형을 벡터 또는 데이터 프레임 자료형으로 형변환하는 함수
※ count(data, 컬럼명, sort=F): data에서 해당 컬럼명의 요소별 개수 리턴
#Q1. group_by, summarize 함수를 사용하여 대륙별 평균 GDP 테이블을 생성하세요.
#대륙별 평균 GDP 계산
gdp_bycontinents <- gapminder %>% group_by(continent) %>% summarize(mean_gdpPercap=mean(gdpPercap))
#Q2. 아메리카대륙에 대한 데이터 프레임을 구하고, 총 몇 개의 행이 있는지 확인하세요.
America <- gapminder %>% filter(continent == "Americas")
America %>% nrow() #300
#Q3. 아메리카대륙 인구가 3천만 이상인 데이터 프레임을 구하고, 해당 데이터 프레임의 ‘country’ 컬럼 별 행 개수를 구하세요.'
America %>% filter(pop >= 30000000) %>% count(country, sort=T)
#Q4. Q3에서 확인한 결과, 아메리카대륙 중 55년 내내 인구 3천만명이상인 나라는 3곳입니다. Brazil, Mexico, United States의 년도 별 인구수를 한 그래프에 나타내세요.
#min, max 값 계산
min <- gapminder %>% filter(country == "Brazil" | country == "Mexico" | country == "United States") %>%
select(pop) %>% min()
max <- gapminder %>% filter(country == "Brazil" | country == "Mexico" | country == "United States") %>%
select(pop) %>% max()
#그래프 그리기
gapminder %>% filter(country == "Brazil") %>% select(year, pop) %>% plot(type='o', col="red", ylim=c(min,max))
gapminder %>% filter(country == "Mexico") %>% select(year, pop) %>% lines(type='o', col="blue")
gapminder %>% filter(country == "United States") %>% select(year, pop) %>% lines(type='o', col="green")
#범례 그리기
legend("topleft",legend=c("Brazil", "Mexico", "United States"), fill=c("red", "blue","green"))
[184차시]dplyr 패키지 정리 및 실습
QUIZ
- 다음 중 dplyr의 장점이 아닌 것은? (4)
1️⃣ 데이터 전처리를 보다 쉽게 할 수 있도록 도와준다.
2️⃣ C++ 기반 패키지이며, 처리속도가 빠르다.
3️⃣ 가독성 향상에 도움을 주는 파이프 연산자를 제공한다.
4️⃣ 다양한 시각화 툴을 제공한다. - dplyr 함수인 distinct는 데이터 프레임에서 특정 컬럼의 중복 값 을 제거하는 기능을 가진다.
- dplyr 함수인 select는 데이터 프레임에서 원하는 컬럼만 추출할 수 있게하는 기능을 가진다.
- dplyr 함수인 mutate는 기존에 있는 데이터를 사용하여 새롭게 열 컬럼을 생성하는 기능을 가진다.
- dplyr 함수 중 summary 함수는 그룹 단위 통일기능 수행 후, 새로운 데이터프레임에 수행 결과를 통합하는 기능을 가진다.
실습
library(dplyr)
#Q1
data <- read.csv('TravelMode.csv')
head(data)
dim(data) # (840 10)
#Q2
avg_table <- data %>% group_by(mode) %>% summarize(gcostAgv=mean(gcost))
avg_table
#Q3
avg_table <- avg_table %>% as.data.frame()
label <- paste(avg_table$mode, "(", round(avg_table$gcostAgv / sum(avg_table$gcostAgv) *100,1), "% )" )
pie(avg_table$gcostAgv,labels = label)
✍️ 마무리하며
아직 R에 대해 완벽하게는 모르지만 확실히 파이썬보다 간단하게 원하는 자료를 뽑아낼 수 있는 경우가 있는 것 같다. 특히 파이프 연산자가 가장 직관적으로 편리하게 다가왔다.
여러가지 프로그램들을 공부하면서 느끼는 점은 모든 프로그램들이 알게 모르게 비슷한 사고를 요한다는 것이다! (데이터 분석에 집중해서 공부하고 있기 때문에 더 그런걸지는 몰라도) 파이썬을 처음 공부할 때는 정말 쇠귀에 경읽기에서 소를 담당하는 나였지만 이제는 어느정도 흐름은 잡은채로 공부하고 있는 것 같다! 물론 한번듣고 모든 내용을 기억할 수는 없지만 꼼꼼히 복습해서 확실하게 내 지식으로 만들고 싶다💪
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
📌 본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'교육 > 유데미 스타터스 4기' 카테고리의 다른 글
| [👩💻TIL 14일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.23 |
|---|---|
| [👩💻TIL 13일차 ] 유데미 스타터스 취업 부트캠프 4기 (1) | 2023.02.23 |
| [👩💻TIL 11일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.20 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 2주차 학습 일지 (1) | 2023.02.17 |
| [👩💻TIL 10일차 ] 유데미 스타터스 취업 부트캠프 4기 (0) | 2023.02.17 |



